在当今数字化的时代,数据一致性成为了保障系统稳定和可靠运行的关键因素,RDS(Relational Database Service,关系型数据库服务)和 Redis(Remote Dictionary Server,远程字典服务)作为常用的数据库技术,如何确保它们的数据一致性是一个值得深入探讨的重要课题。
RDS 通常用于处理结构化数据,遵循严格的事务机制来保证数据的一致性,在事务执行过程中,要么所有操作都成功完成,要么全部回滚,从而确保数据始终处于一致的状态,而 Redis 作为一种基于内存的非关系型数据库,其数据一致性的保障方式则有所不同。

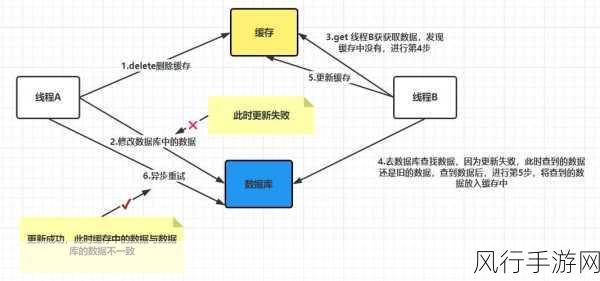
Redis 本身在处理数据时具有较高的性能和灵活性,但也正因如此,其数据一致性的保障需要更多的策略和技巧,在分布式环境下,Redis 可以通过主从复制机制来实现数据的同步,主节点负责接收写入操作,并将数据变更同步到从节点,这种同步过程并非实时且无延迟的,可能会存在短暂的数据不一致情况。
为了进一步提高 RDS 和 Redis 数据一致性的保障水平,我们可以采取一些有效的措施,在 RDS 方面,合理设计数据库架构、优化事务处理逻辑以及定期进行数据备份和恢复测试都是非常重要的,对于 Redis 配置合适的持久化策略、监控主从复制的延迟情况以及及时处理可能出现的故障节点等操作能够增强数据的一致性和可靠性。
在实际应用中,还需要根据具体的业务需求和场景来选择合适的数据库技术和策略,如果业务对数据一致性要求极高,可能需要更多地依赖 RDS 的强事务特性,而对于一些对性能要求较高、能够容忍一定程度数据不一致的场景,Redis 则能发挥其优势。
RDS 和 Redis 数据一致性的保障并非一蹴而就,需要综合考虑多种因素,并采取针对性的措施和策略,只有这样,才能在充分发挥它们各自优势的同时,确保数据的准确、完整和一致,为业务的稳定运行提供坚实的支撑。