OpenStack 作为一款强大的开源云计算平台,其数据库的高效管理至关重要,在处理大量数据时,数据压缩成为了提高数据库性能和节省存储空间的关键策略,OpenStack 数据库如何进行数据压缩呢?
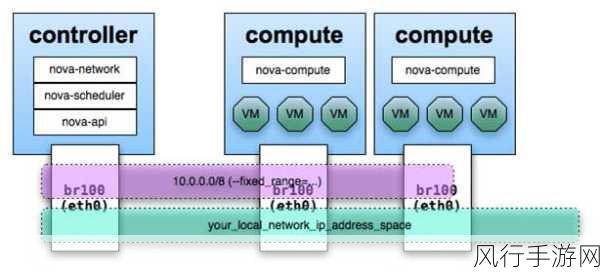
要理解 OpenStack 数据库的数据压缩,我们首先需要明晰 OpenStack 数据库的架构和数据特点,OpenStack 通常使用关系型数据库(如 MySQL 或 PostgreSQL)来存储其配置信息、用户数据以及各种运行时的状态信息,这些数据在不断的生成和更新过程中,容易导致数据量的快速增长。

数据压缩的方法多种多样,常见的有基于行压缩和基于列压缩两种方式,对于 OpenStack 数据库而言,基于列压缩可能更为适用,因为 OpenStack 中的数据往往具有较强的列相关性,例如同一类型的配置参数或者相似的数据字段,通过对这些具有相关性的列进行压缩,可以显著减少数据存储空间。
在实现数据压缩时,还需要考虑到对数据库性能的影响,过度的压缩可能会导致数据读写的延迟增加,从而影响 OpenStack 系统的整体性能,需要在压缩比和性能之间找到一个平衡点。
选择合适的数据压缩算法也是至关重要的,不同的算法在压缩效率、压缩比和计算资源消耗等方面存在差异,LZO 算法压缩速度快,但压缩比较低;而 GZIP 算法压缩比较高,但压缩速度相对较慢。
还需要对 OpenStack 数据库的配置进行优化,以适应数据压缩的需求,这包括调整数据库的缓存大小、优化查询语句等,以确保在进行数据压缩的情况下,数据库仍然能够高效地响应各种操作请求。
定期对压缩效果进行评估和监测也是必不可少的,通过观察数据库的存储空间使用情况、数据读写性能等指标,及时调整压缩策略和算法,以达到最佳的效果。
实现 OpenStack 数据库的数据压缩并非一蹴而就,需要综合考虑数据特点、算法选择、性能平衡以及配置优化等多个方面,只有通过不断的实践和优化,才能在节省存储空间的同时,保障 OpenStack 系统的稳定高效运行。