在当今大数据时代,Hive 作为一种常用的数据仓库工具,其数据导入功能对于数据处理和分析至关重要,Hive 表类型多样,包括内部表、外部表、分区表等,不同类型的表在数据导入方式上也有所差异。
要实现 Hive 表类型数据的有效导入,我们需要先了解 Hive 所支持的数据格式,常见的数据格式有文本格式(如 CSV)、Parquet 格式、ORC 格式等,每种格式都有其特点和适用场景。
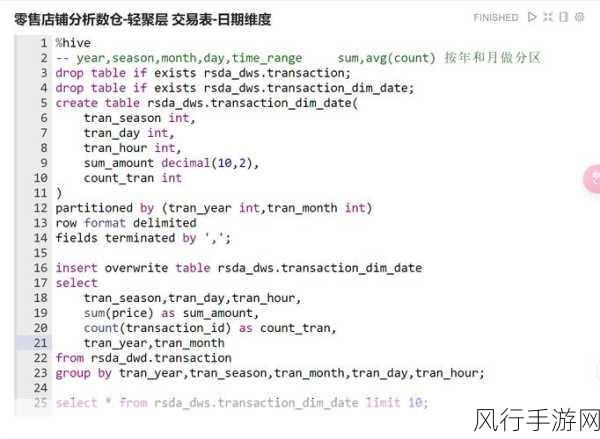
让我们深入探讨一下不同类型 Hive 表的数据导入方法,对于内部表,我们可以使用“LOAD DATA”语句将本地文件或 HDFS 上的文件加载到表中,如果我们有一个 CSV 文件位于本地路径“/data/file.csv”,要将其导入到名为“my_internal_table”的内部表中,可以执行以下命令:
LOAD DATA LOCAL INPATH '/data/file.csv' INTO TABLE my_internal_table;
而对于外部表,其数据实际上并不由 Hive 管理,只是通过表的定义来关联外部数据的位置,导入外部表数据时,同样可以使用类似的语句,但需要注意指定“EXTERNAL”关键字。
分区表是 Hive 中提高查询效率的重要手段,在导入分区表数据时,需要明确指定分区的值,假设我们有一个按日期分区的表“my_partitioned_table”,分区字段为“date”,要导入 20230801 分区的数据,可以这样操作:
LOAD DATA LOCAL INPATH '/data/20230801_file.csv' INTO TABLE my_partitioned_table PARTITION (date='20230801');
还可以通过 Sqoop 等工具将关系型数据库中的数据导入到 Hive 表中,Sqoop 能够方便地实现从 MySQL、Oracle 等数据库到 Hive 的数据迁移。
掌握 Hive 表类型数据的导入方法对于高效的数据处理和分析具有重要意义,在实际应用中,我们需要根据数据特点、业务需求以及系统性能等因素,选择合适的数据导入方式和工具,以确保数据的准确性和完整性,为后续的数据分析和挖掘工作打下坚实的基础。