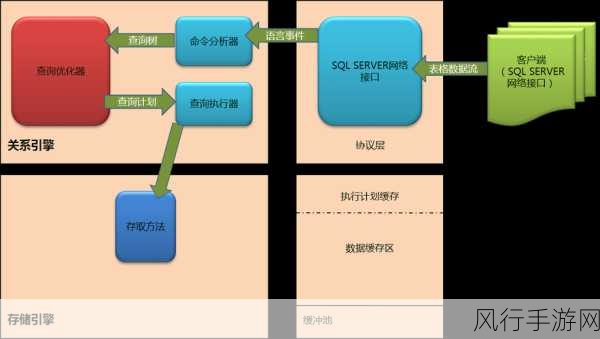
在当今数字化时代,数据量呈现爆炸式增长,如何有效地处理大数据量成为了众多企业和开发者面临的重要挑战,Redis 分布式数据库作为一种高性能的内存数据库,在处理大数据量方面具有独特的优势和策略。
Redis 之所以能够在处理大数据量时表现出色,一个关键原因在于其出色的数据结构设计,它提供了多种数据结构,如字符串、哈希、列表、集合和有序集合等,每种数据结构都适用于不同的场景,使得数据的存储和操作更加灵活高效,对于需要快速检索和更新的数据,可以使用哈希结构;而对于需要保持顺序的数据,可以选择有序集合。
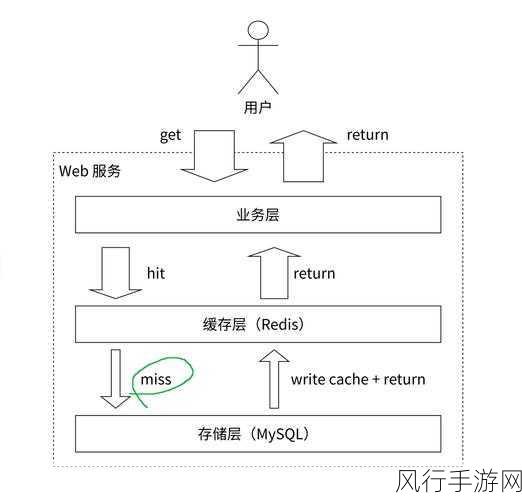
Redis 分布式数据库采用了主从复制和哨兵机制来确保数据的高可用性和可靠性,主从复制可以将数据同步到多个从节点,从而实现数据的备份和扩展读性能,哨兵机制则能够监控主节点和从节点的状态,在主节点出现故障时自动进行故障切换,保证系统的持续稳定运行。
Redis 还支持分片技术,通过将数据分布在多个节点上,实现了横向扩展,能够处理更大规模的数据量,在进行分片时,需要合理规划数据的分布策略,以确保数据的均衡分布和高效访问。
为了进一步优化 Redis 处理大数据量的性能,还可以采取一些措施,合理设置缓存的过期时间,及时清理不再使用的数据,避免内存的过度占用,对热点数据进行特殊处理,提高其访问速度。
在实际应用中,还需要结合具体的业务需求和场景,对 Redis 进行精细的配置和优化,调整内存分配策略、优化网络参数等,以充分发挥其性能优势。
Redis 分布式数据库在处理大数据量方面具有强大的能力,但要充分发挥其优势,需要我们深入理解其原理和机制,并根据实际情况进行合理的设计和优化,只有这样,才能让 Redis 更好地服务于我们的业务,应对大数据量带来的挑战。