在当今数字化时代,数据的处理和查询速度对于企业和开发者来说至关重要,ClickHouse 作为一款高性能的列式数据库管理系统,其数据查询缓存功能是提升查询效率的关键之一,究竟如何有效地利用 ClickHouse 进行数据查询缓存呢?
ClickHouse 的数据查询缓存并非简单的配置即可生效,而是需要对其工作原理和适用场景有深入的理解,它通过将经常执行且结果相对稳定的查询结果进行缓存,从而在后续相同查询请求到来时,能够快速返回结果,减少重复计算和数据读取的时间开销。
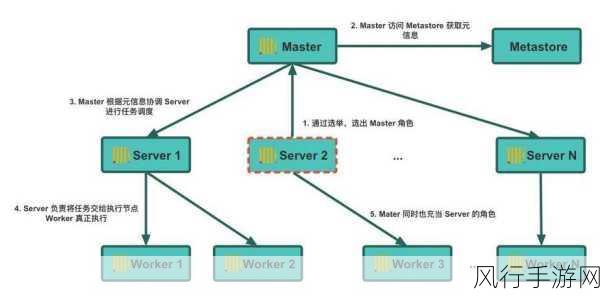
要实现有效的数据查询缓存,第一步是要明确缓存的策略,这包括确定哪些查询适合被缓存,以及缓存的有效期等,那些执行频率高、数据变化不频繁的查询是理想的缓存对象,一些定期生成的报表查询,或者对于相对静态的基础数据的查询。
需要合理配置 ClickHouse 的缓存相关参数,这需要根据实际的业务需求和系统资源进行调整,设置缓存的大小,以确保能够容纳足够多的有效缓存数据,同时又不会过度消耗内存资源。
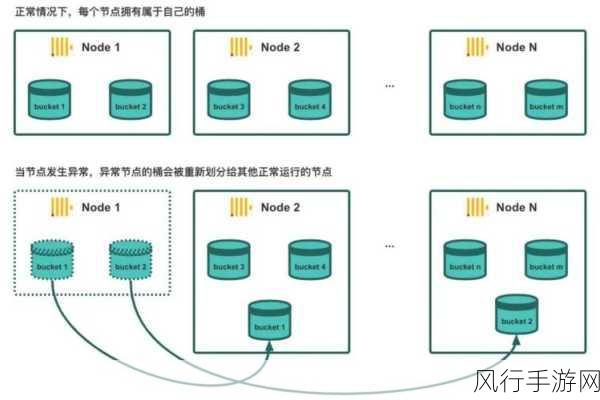
还需要关注缓存的更新机制,当相关的数据发生变更时,及时清除对应的缓存,以保证查询结果的准确性,这可以通过监听数据变更事件或者设置定时刷新来实现。
在实际应用中,还可以结合其他优化手段来进一步提升查询性能,优化表结构、建立合适的索引、合理利用分区等,这些措施与数据查询缓存相互配合,能够为用户带来更加流畅和高效的数据查询体验。
熟练掌握 ClickHouse 的数据查询缓存功能,需要深入了解其原理和机制,并结合实际的业务场景进行合理的配置和优化,只有这样,才能充分发挥 ClickHouse 的强大性能,满足不断增长的业务需求。