深入探究 HBase 数据类型与行键
HBase 作为一种分布式的、面向列的开源数据库,在大数据处理领域发挥着重要作用,其数据类型和行键的设计与运用,直接影响着数据存储和查询的效率与性能。
HBase 的数据类型相对较为简单和灵活,字节数组(byte array)是最基本的数据类型,可以用于存储各种类型的数据,如字符串、整数、浮点数等,HBase 还支持布尔型(boolean)、长整型(long)等常见的数据类型,这种简单的数据类型设计,使得 HBase 在处理大规模数据时具有较高的性能和效率。

行键在 HBase 中扮演着至关重要的角色,行键的设计不仅决定了数据在表中的分布方式,还直接影响着数据的查询性能,一个好的行键设计应该具备唯一性、均匀分布性和可读性等特点。
唯一性是行键的基本要求,它确保了每一行数据都能够被准确地识别和访问,均匀分布性则有助于避免数据倾斜,使得数据在各个存储节点上能够均衡分布,从而提高系统的整体性能,可读性在某些场景下也是非常重要的,它可以让开发者和运维人员更直观地理解数据的含义和逻辑。
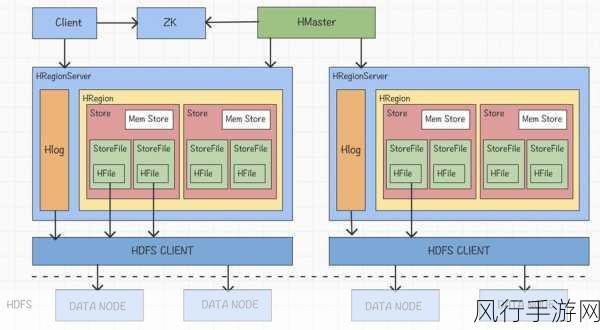
在实际应用中,行键的设计需要结合具体的业务需求和数据特点来进行,对于时间序列数据,可以将时间戳作为行键的一部分,以便按照时间顺序进行高效的查询,对于地理位置相关的数据,可以将经纬度信息进行编码后作为行键的组成部分,从而实现基于地理位置的快速查询。
HBase 还支持复合行键的设计,通过将多个字段组合成一个行键,可以更加灵活地满足复杂的业务需求,但需要注意的是,复合行键的设计要合理,避免过度复杂导致查询和管理的困难。
深入理解 HBase 的数据类型和行键对于充分发挥其性能优势、实现高效的数据存储和查询至关重要,在实际的开发和应用中,我们需要根据具体的业务场景和数据特点,精心设计数据类型和行键,以构建一个高性能、可靠的大数据存储系统。