深度剖析,SparkSQL 优化与性能提升的关键策略
SparkSQL 作为大数据处理领域的重要工具,其性能表现直接影响着数据分析和处理的效率,要实现 SparkSQL 的性能优化,需要从多个方面入手。
在数据处理过程中,合理的数据存储格式选择至关重要,Parquet 和 ORC 等列式存储格式能够大幅提升查询性能,因为它们在读取特定列数据时避免了不必要的行扫描。
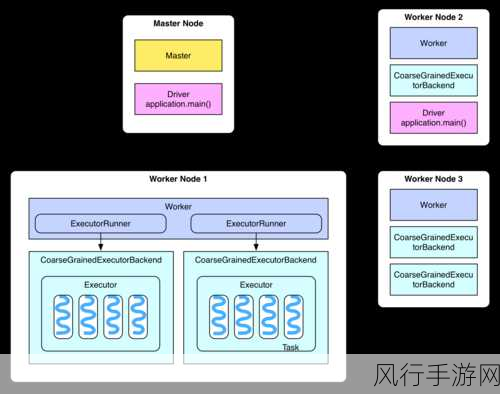
数据分区也是优化的关键环节之一,通过对数据进行合适的分区,可以减少数据的扫描范围,提高查询的局部性,按照时间、地域等常见的查询维度进行分区,能够让查询在特定分区内快速定位所需数据。
优化索引的使用能够显著加快查询速度,在 SparkSQL 中,可以利用 Bloom Filter 索引、Bitmap 索引等技术,提前过滤掉不满足条件的数据,减少实际处理的数据量。
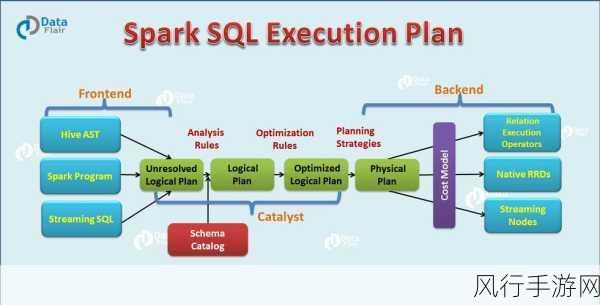
优化查询语句的编写同样不可忽视,避免不必要的全表扫描,合理使用聚合函数和连接操作,能够有效降低计算开销,在条件过滤中,尽量使用更具选择性的条件,提前减少数据量。
对于复杂的查询任务,可以考虑将其分解为多个简单的子查询,逐步优化每个子查询的性能,然后再进行组合。
缓存经常使用的数据也是提升性能的有效手段,将频繁访问的数据缓存在内存中,避免重复计算和数据读取,能够大大缩短查询响应时间。
在实际应用中,不断监测和分析 SparkSQL 任务的执行计划和性能指标,根据具体情况进行针对性的优化调整,才能真正发挥 SparkSQL 的强大性能,为数据处理和分析提供高效支持。
要提升 SparkSQL 的性能表现,需要综合运用上述多种优化策略,并结合具体的业务需求和数据特点,不断探索和实践,以达到最佳的性能效果。