掌握 Python 爬虫框架的秘诀指南
Python 爬虫框架作为网络数据采集的强大工具,吸引着众多开发者的目光,要想精通这一领域,掌握有效的学习技巧至关重要。
爬虫框架的学习并非一蹴而就,它需要我们有系统性的规划和持之以恒的实践,我们不能仅仅满足于理论知识的积累,更要注重实际操作中的经验总结。
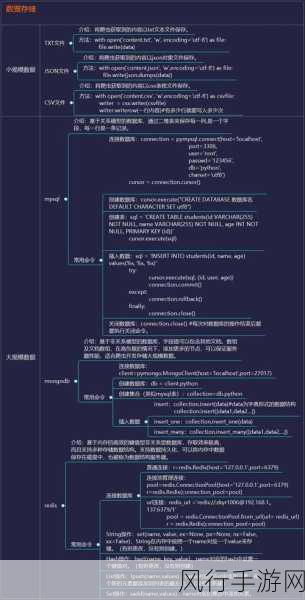
学习 Python 爬虫框架,要从基础语法入手,熟悉 Python 语言的基本结构、数据类型、控制流语句等是必不可少的,只有在牢固掌握这些基础知识的前提下,才能更好地理解和运用爬虫框架。
深入研究 HTTP 协议也是关键的一环,了解 HTTP 请求与响应的原理、状态码的含义以及常见的请求方法,将为我们编写高效的爬虫程序提供有力支撑。

要善于利用开源的爬虫框架资源,Scrapy 就是一个非常流行且功能强大的框架,通过阅读其官方文档、示例代码以及相关的技术博客,可以快速掌握框架的核心概念和使用方法。
在实践过程中,要注重代码的规范性和可读性,良好的代码结构和注释能够让我们在后续的维护和优化中事半功倍。
还需要关注反爬虫机制,许多网站为了保护自身数据,会采取各种反爬虫措施,我们要学会识别和应对这些反制手段,例如设置合理的请求间隔、模拟真实的用户行为等。
学习 Python 爬虫框架还需要保持对新技术和行业动态的敏感度,网络技术不断发展,爬虫框架也在不断更新和完善,及时了解最新的技术趋势和最佳实践,能够让我们始终站在技术前沿。
学习 Python 爬虫框架需要我们有坚定的决心、系统的学习方法和大量的实践,只要我们坚持不懈,就一定能够在这个领域取得优异的成果,为我们的数据采集和分析工作提供强大的支持。