SQL Input 处理大量数据的高效之道
在当今数字化的时代,数据量呈爆炸式增长,对于数据库管理和处理的要求也日益提高,当面对大量数据时,如何有效地通过 SQL Input 进行处理成为了众多开发者和数据分析师关注的焦点。
SQL 作为一种强大的关系型数据库操作语言,在处理大量数据方面具有独特的优势和方法,要实现高效处理,关键在于合理的优化策略和正确的操作技巧。
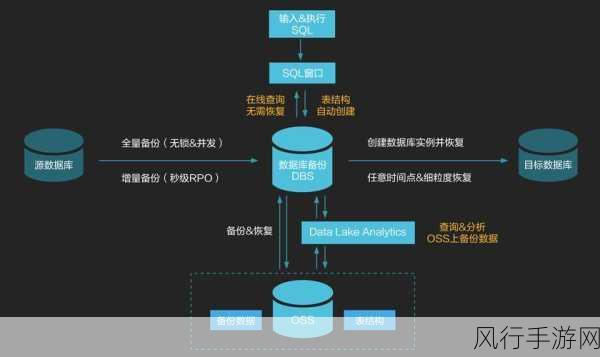
从数据存储结构的角度来看,合理的表设计是基础,在创建表时,应根据数据的特点和使用场景,选择合适的数据类型和索引,对于经常用于查询和连接的字段,建立适当的索引可以显著提高查询效率,但需要注意的是,过多或不当的索引也可能会带来性能的下降。
在数据加载阶段,批量加载往往比逐行插入更高效,可以使用 SQL 的批量导入功能,将大量数据一次性加载到数据库中,在加载前对数据进行必要的清理和预处理,能够减少后续处理中的错误和异常。
查询语句的优化也是至关重要的一环,避免使用全表扫描,尽量利用索引进行查询,条件过滤要精确,减少不必要的数据返回,对于复杂的查询,可以考虑分解为多个简单的子查询,逐步优化每个子查询的性能。
合理利用数据库的分区技术可以将大规模数据分割成多个较小的部分,从而提高数据处理的效率,根据数据的特征,如时间、地域等进行分区,使得在查询特定分区的数据时,能够快速定位和处理。
数据库的配置参数也会对处理大量数据的性能产生影响,根据硬件资源和实际业务需求,调整缓冲区大小、并发连接数等参数,以达到最佳的性能状态。
处理大量数据的 SQL Input 并非一蹴而就,需要综合考虑多个方面的因素,并不断进行测试和优化,只有这样,才能在面对海量数据时,依然能够快速、准确地获取所需信息,为业务决策提供有力支持。