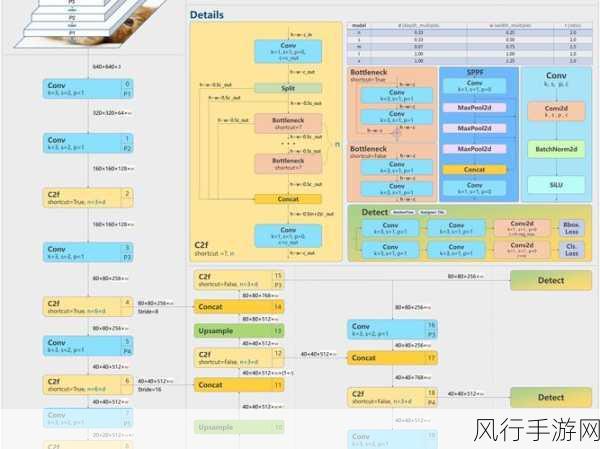
在当今大数据处理的领域中,Spark 凭借其强大的功能和出色的性能表现,成为了众多开发者和数据工程师的首选工具,而 Spark Schema 作为其中的一个重要概念,对性能有着深远且多方面的影响。
Spark Schema 定义了数据的结构和类型信息,它就像是数据的蓝图,为 Spark 在处理数据时提供了清晰的指导,一个准确和优化的 Spark Schema 能够显著提升数据处理的效率,减少不必要的计算和资源消耗。
当 Spark 读取数据时,如果没有预先定义好 Schema,它需要在运行时进行推断,这是一个耗时且可能不准确的过程,相反,若事先明确了 Schema,Spark 能够直接按照预定的结构进行数据读取和处理,避免了额外的推断开销。
Schema 中的数据类型也至关重要,合理选择数据类型不仅能够节省存储空间,还能在计算过程中提高运算速度,对于整数类型,如果能准确预估数据的范围,选择合适的整数类型(如 short、int 或 long)可以避免不必要的类型转换和内存占用。

优化的 Schema 还能有助于数据的分区和并行处理,通过根据关键字段进行合理的分区,可以让 Spark 在处理大规模数据时,将任务更均匀地分配到不同的节点上,实现并行计算的最大化,从而大大缩短处理时间。
如果 Schema 设计不合理,也会给性能带来负面影响,过于复杂或冗余的 Schema 可能导致数据处理逻辑变得混乱,增加计算的复杂性和时间成本。
在实际应用中,为了充分发挥 Spark Schema 对性能的积极影响,开发者需要深入了解业务需求和数据特点,精心设计 Schema,不断进行测试和优化,只有这样,才能确保 Spark 在处理数据时达到最佳的性能表现,为企业的数据分析和决策提供有力支持。
Spark Schema 虽然看似只是数据结构的定义,但它却是影响 Spark 性能的关键因素之一,正确理解和优化 Spark Schema,对于提升大数据处理的效率和质量具有不可忽视的重要意义。