探索 Python 数据仓库提升效率的关键策略
在当今数字化时代,数据成为了企业和组织决策的重要依据,Python 作为一种强大的编程语言,在数据仓库领域发挥着重要作用,如何利用 Python 数据仓库提升效率,是众多开发者和数据分析师面临的挑战。
要提升 Python 数据仓库的效率,合理的架构设计至关重要,一个良好的架构能够确保数据的流畅存储和快速访问,采用分层存储的方式,将频繁访问的数据存储在高速存储介质中,而将不常使用的数据存储在成本较低的介质上,优化数据模型,减少冗余和重复数据,能够有效降低数据存储和处理的成本。
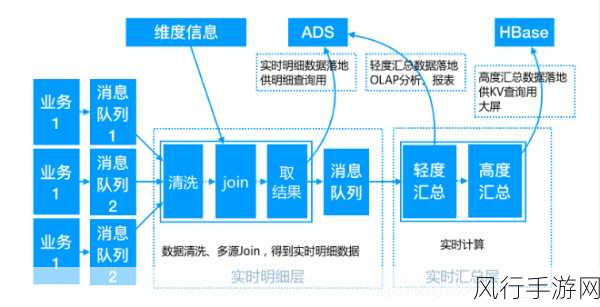
数据预处理是提升效率的另一个关键环节,在数据进入仓库之前,对其进行清洗、转换和验证,可以避免后续处理中的错误和不必要的计算,去除重复数据、纠正错误格式、填充缺失值等操作,能够使数据更加准确和完整,为后续的分析和处理奠定坚实的基础。
索引的合理运用也是提高效率的重要手段,通过为关键列创建合适的索引,可以大大加快数据的查询速度,但需要注意的是,过多或不恰当的索引可能会带来负面影响,因此需要根据实际业务需求和数据特点进行精心设计。
并行处理技术在提升效率方面也具有显著效果,Python 提供了多种并行处理的库和框架,如 multiprocessing 和 concurrent.futures,可以将任务分解为多个子任务并同时执行,充分利用多核 CPU 的计算能力,从而显著缩短处理时间。
优化查询语句也是不可忽视的一环,编写高效的 SQL 查询语句,避免不必要的全表扫描和复杂的连接操作,能够大大提高数据检索的效率,对查询结果进行缓存,对于重复查询的场景,可以直接返回缓存结果,避免重复计算。
定期对数据仓库进行维护和优化同样重要,包括清理过期数据、重组数据表、更新统计信息等操作,能够保持数据仓库的良好性能。
提升 Python 数据仓库的效率需要综合考虑架构设计、数据预处理、索引运用、并行处理、查询优化和定期维护等多个方面,只有在每个环节都精心优化,才能充分发挥 Python 数据仓库的优势,为业务决策提供快速、准确的数据支持。
在实际应用中,需要根据具体的业务场景和数据特点,灵活选择和组合上述策略,不断探索和创新,以满足不断变化的业务需求和性能要求,相信随着技术的不断发展和经验的积累,我们能够更好地利用 Python 数据仓库提升效率,为数据驱动的决策提供更有力的保障。