探索 Python 网络爬虫所需的关键知识领域
在当今数字化的时代,数据的价值日益凸显,而网络爬虫成为了获取大量数据的有效手段之一,如果您想要掌握 Python 网络爬虫技术,以下是一些必须学习的重要知识。
网络基础知识是不可或缺的一环,您需要了解 HTTP 协议、TCP/IP 协议等基本概念,明白客户端与服务器之间的通信原理,这有助于您理解网页是如何被请求和响应的,为后续的爬虫编写打下坚实的基础。
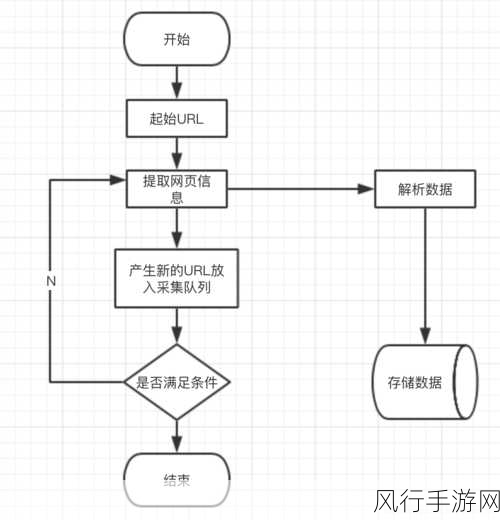
网页结构和 HTML、CSS 知识也至关重要,熟悉 HTML 标签的含义、CSS 样式的作用,能够帮助您准确地定位和提取所需的数据,通过对网页源代码的分析,您可以快速找到目标数据所在的位置。
正则表达式是处理文本数据的强大工具,在网络爬虫中,经常需要从大量的文本中筛选出特定的信息,掌握正则表达式的语法和用法,能够高效地进行数据的匹配和提取。
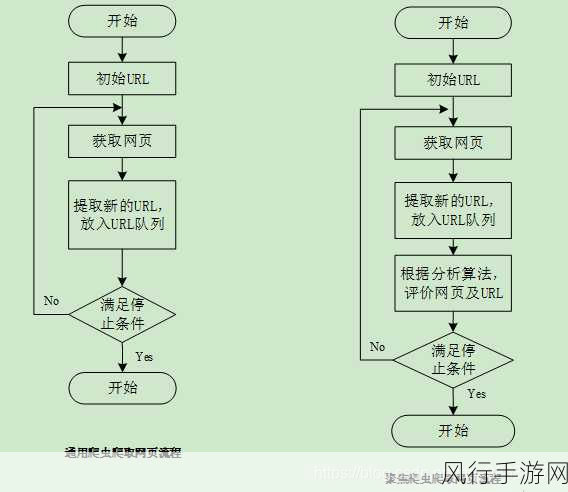
Python 编程语言的熟练运用是核心,了解 Python 的基本语法、数据结构、控制流等,能够让您编写出清晰、高效的爬虫代码,掌握一些常用的 Python 库,如 requests 用于发送网络请求,BeautifulSoup 用于解析 HTML 等,会极大地提高开发效率。
反爬虫机制和应对策略也是必须要考虑的,许多网站为了保护自身数据和资源,设置了反爬虫措施,您需要学会识别常见的反爬虫手段,如 IP 封禁、验证码、访问频率限制等,并采取相应的应对方法,如使用代理 IP、设置合理的请求间隔等。
数据存储和处理能力同样重要,爬取到的数据需要进行有效的存储和处理,以便后续的分析和使用,您可以选择将数据存储在数据库中,如 MySQL、MongoDB 等,或者以文件形式保存,如 CSV、JSON 等。
除此之外,还需要具备良好的问题解决能力和学习能力,网络爬虫开发过程中可能会遇到各种各样的问题,如网页结构变化、反爬虫机制升级等,能够灵活运用所学知识,快速找到解决方案,并不断学习和适应新的技术和变化,是成为一名优秀爬虫开发者的关键。
学习 Python 网络爬虫需要综合掌握多方面的知识和技能,不断实践和积累经验,才能在数据获取的道路上越走越远,为数据分析和应用提供有力的支持。