Python 网络爬虫技术,应对变化网页的策略与技巧
在当今数字化的时代,网络数据的价值日益凸显,网络爬虫作为获取网络数据的重要手段,其应用范围越来越广泛,网页的变化性给 Python 网络爬虫技术带来了不小的挑战,如何有效地应对这种变化,成为了众多开发者和数据分析师关注的焦点。
网页的变化可能源于多种因素,比如网站的更新维护、页面布局的调整、内容的动态生成等,这些变化使得传统的爬虫方法往往难以奏效,需要我们采用更加灵活和智能的策略。

要应对变化网页,深入理解网页的结构和规律是关键,通过对目标网页的 HTML 代码进行分析,我们可以找出其中相对稳定的元素和特征,以此为基础构建爬虫的逻辑,某些网页的关键信息可能总是位于特定的标签或类名之下,我们就可以依据这些固定的标识来提取数据。
设置合理的爬虫频率也非常重要,过于频繁的访问可能会被网站视为恶意行为而加以限制,甚至导致爬虫被封禁,需要根据网站的性质和规定,以及数据更新的需求,来确定一个既能保证获取到最新数据,又不会对网站造成过大负担的访问频率。
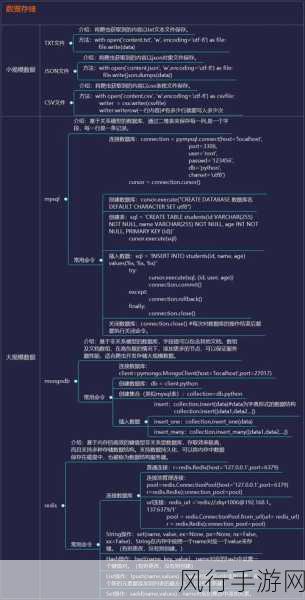
运用一些先进的技术和工具也能增强爬虫应对变化网页的能力,使用分布式爬虫框架可以提高爬虫的效率和稳定性;利用机器学习算法对网页的变化模式进行预测,从而提前做好应对准备。
还需要处理好异常情况,当爬虫遇到网页结构变化、访问错误等问题时,要有相应的错误处理机制,能够自动记录错误信息、重新尝试访问或者切换备用策略。
Python 网络爬虫技术在应对变化网页时,需要综合运用多种策略和方法,不断优化和调整爬虫的设计与实现,只有这样,才能在复杂多变的网络环境中,高效、准确地获取到有价值的数据,为各种应用提供有力的支持。
在未来,随着网络技术的不断发展和网页形式的日益多样化,应对变化网页的挑战将持续存在,但相信凭借不断的创新和探索,Python 网络爬虫技术一定能够不断进化,更好地满足人们对于数据获取和处理的需求。