深度解析 Spark MapPartition 的适用场景
在大数据处理领域,Spark 凭借其强大的功能和出色的性能表现,成为了众多开发者和数据分析师的首选工具,MapPartition 操作在特定场景下能够发挥出独特的优势,为数据处理带来更高的效率和更好的效果。
MapPartition 操作是 Spark 中的一种数据处理方式,它与常规的 Map 操作有所不同,在 Map 操作中,每个元素都会被单独处理,而 MapPartition 则是针对每个分区进行处理,这意味着可以在一个分区内对多个元素进行一次性的处理,从而减少了函数调用的开销。
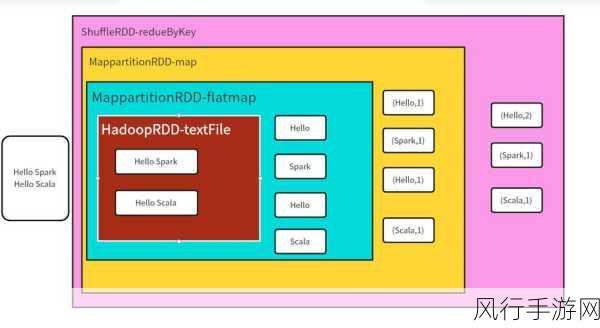
究竟在哪些场景下适合使用 MapPartition 呢?
当需要对数据进行批量处理时,MapPartition 是一个不错的选择,在进行数据清洗和转换的过程中,如果需要对同一分区内的大量数据执行相同的操作,如格式转换、数据填充等,使用 MapPartition 可以显著提高处理效率,因为一次性处理一个分区的数据,避免了对每个元素单独进行处理时的重复操作和函数调用。
在与外部资源进行交互时,MapPartition 也能展现出其优势,当需要从数据库中读取数据或者向数据库写入数据时,如果采用 Map 操作,可能会导致频繁地建立和关闭连接,从而影响性能,而使用 MapPartition ,可以在每个分区内只建立一次连接,然后对分区内的数据进行批量读写操作,大大减少了连接开销。
对于一些需要初始化和维护全局状态的操作,MapPartition 也更为适用,假设需要在处理数据的过程中计算某个全局的统计信息,或者维护一个全局的缓存,使用 MapPartition 可以在分区处理的开始阶段进行初始化,并在整个分区处理过程中持续使用和更新。
需要注意的是,MapPartition 并非在所有情况下都是最优选择,如果分区的数据量过大,可能会导致内存占用过高,从而引发性能问题,如果分区内的数据分布不均匀,也可能会导致某些分区处理时间过长,影响整体的处理效率。
MapPartition 在特定的场景下能够为 Spark 数据处理带来显著的性能提升,但在使用时需要充分考虑数据的特点和处理需求,以确保能够发挥其最大的优势,在实际应用中,需要根据具体情况进行测试和优化,选择最适合的处理方式,从而实现高效、准确的数据处理。