掌握 HBase 分布式数据库数据恢复的关键技巧
HBase 分布式数据库作为大数据处理领域的重要工具,在实际应用中,数据恢复是一个至关重要的环节,当面临数据丢失或损坏的情况时,有效的数据恢复策略能够最大程度地减少损失,并确保业务的正常运行。
HBase 数据库的数据恢复并非一蹴而就,它需要我们对其架构和工作原理有深入的理解,HBase 是基于 Hadoop 生态系统构建的,采用了分布式存储架构,将数据分散存储在多个节点上,这意味着数据恢复过程需要协调多个节点的操作,以确保恢复的完整性和准确性。
在进行数据恢复之前,我们必须明确数据丢失的原因,可能是硬件故障、网络问题、软件错误或者人为误操作等,针对不同的原因,采取的恢复策略也会有所差异,如果是硬件故障导致的数据丢失,我们需要先修复硬件问题,然后再进行数据恢复操作。
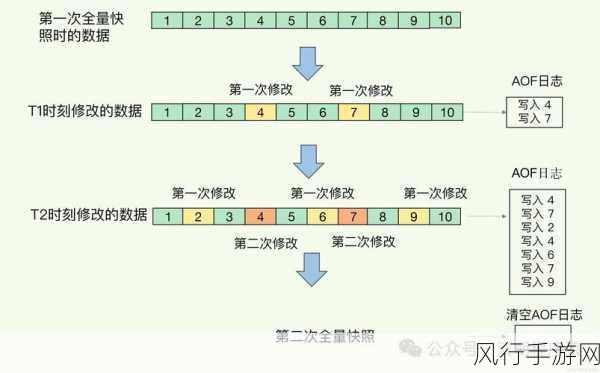
要成功恢复 HBase 数据库中的数据,备份是关键,定期进行数据备份是预防数据丢失的重要手段,备份可以采用全量备份和增量备份相结合的方式,以提高备份效率和恢复的灵活性,备份的存储位置也需要精心选择,确保备份数据的安全性和可用性。
当确定需要进行数据恢复时,我们可以利用 HBase 提供的工具和命令来执行恢复操作,使用Export 和Import 命令可以将数据从一个集群迁移到另一个集群,或者从备份中恢复数据,还可以使用HBase WAL(Write-Ahead Log)来恢复未持久化的数据。
在数据恢复过程中,监控和验证是不可或缺的步骤,我们需要实时监控恢复的进度和状态,确保恢复过程没有出现异常,在恢复完成后,要对恢复的数据进行验证,检查数据的完整性和准确性,以确保恢复的质量。
HBase 分布式数据库的数据恢复是一个复杂但又至关重要的任务,需要我们在日常运维中做好备份工作,了解数据丢失的原因,掌握恢复的方法和工具,并在恢复过程中进行有效的监控和验证,才能确保数据的安全和业务的稳定运行,只有这样,我们才能在面对数据丢失的挑战时,迅速而有效地进行数据恢复,保障业务的连续性和数据的可靠性。