探究 PHP 快速排序在处理大数据时的可行性
在当今数字化时代,数据的规模和复杂性呈爆炸式增长,对于数据处理的效率和准确性提出了更高的要求,快速排序作为一种经典的排序算法,在处理中小规模数据时表现出色,但在面对大数据时,其可行性成为了众多开发者和研究者关注的焦点。
PHP 作为一种广泛应用的脚本语言,常被用于 Web 开发和数据处理任务,当涉及到处理大规模数据时,我们需要仔细评估 PHP 快速排序算法的适用性。
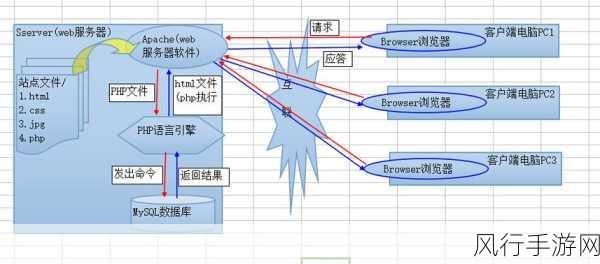
从算法原理来看,快速排序通过选择一个基准元素,将待排序的数组划分为两部分,然后对这两部分分别进行排序,以此递归地完成整个数组的排序,这种分治的思想在理论上具有较高的效率,但在大数据环境下,由于内存和计算资源的限制,可能会遇到一些挑战。
大数据量意味着需要更多的内存来存储数据和中间结果,PHP 在处理大量数据时,可能会面临内存溢出的风险,频繁的递归操作也可能导致栈溢出,从而影响算法的正常执行。
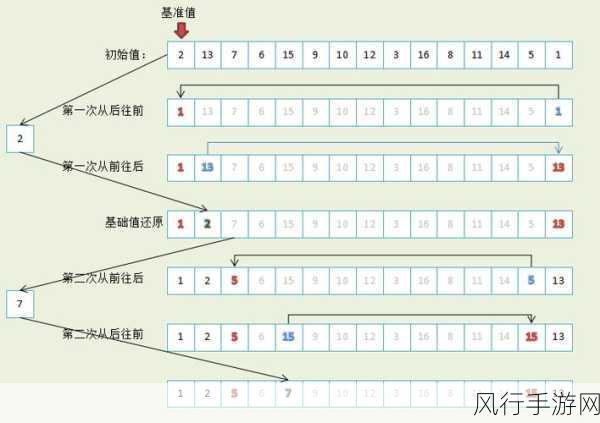
快速排序的性能在很大程度上取决于基准元素的选择,如果选择不当,可能会导致划分不均匀,从而降低排序效率,在大数据场景中,要确保每次选择的基准元素都能有效地划分数据,并非易事。
这并不意味着 PHP 快速排序在处理大数据时完全不可行,通过一些优化策略和技巧,可以在一定程度上提高其性能和可行性。
可以采用外部排序的方法,将大数据分割成较小的块,分别在内存中进行快速排序,然后将排序后的块合并起来,这样可以避免一次性处理大量数据导致的内存问题。
还可以结合其他数据结构和算法,如堆排序、归并排序等,根据数据的特点和具体需求选择最合适的排序方法。
PHP 快速排序在处理大数据时具有一定的可行性,但需要充分考虑数据规模、内存限制和算法优化等因素,在实际应用中,开发者应根据具体情况进行评估和选择,以确保能够高效地完成数据处理任务,只有在深入理解算法原理和掌握优化技巧的基础上,才能更好地应对大数据处理带来的挑战,为用户提供更快速、准确的服务。