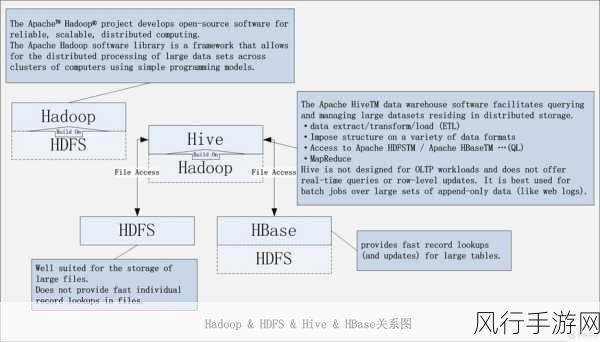
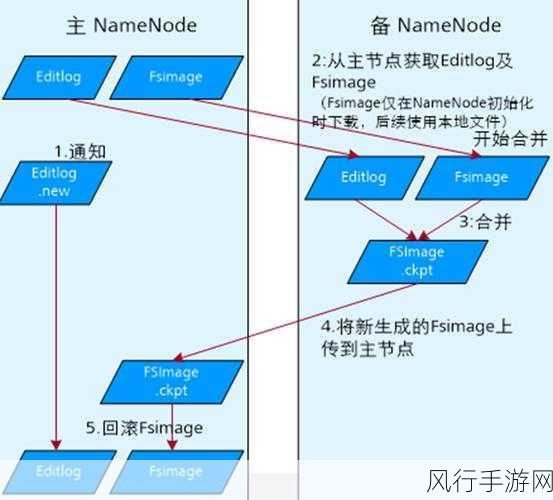
HDFS(Hadoop 分布式文件系统)和 HBase(Hadoop 数据库)是大数据领域中至关重要的技术组件,在处理海量数据时,实现负载均衡对于系统的性能和稳定性至关重要。
负载均衡的目的在于均匀地分配工作负载,避免某些节点过度繁忙而其他节点闲置,从而提高整个系统的资源利用率和响应速度,对于 HDFS 和 HBase 而言,实现负载均衡需要综合考虑多个因素。
HDFS 的负载均衡主要涉及数据块的分布和存储节点的负载情况,它通过一种称为“再平衡”的机制来实现,当系统检测到某些节点的存储使用率过高或过低时,会自动启动再平衡操作,在这个过程中,数据块会在不同的存储节点之间迁移,以达到更均匀的分布,这一过程并非一蹴而就,需要精心设计和优化,以避免对正在进行的读写操作产生过大的影响。
HBase 的负载均衡则更为复杂,因为它不仅要考虑数据的存储分布,还要考虑访问模式和热点数据,HBase 通常使用 Region 作为数据存储和管理的基本单位,当某个 Region 中的数据访问量过大,导致负载过高时,系统会将该 Region 拆分成多个小 Region,并重新分配到不同的节点上,以实现负载的均衡。
为了有效地实现 HDFS 和 HBase 的负载均衡,监控和评估系统的负载状态是关键,通过实时收集节点的资源使用情况、数据存储分布和访问频率等信息,可以准确地判断系统是否处于均衡状态,并及时采取相应的调整措施。
合理的配置参数也是实现负载均衡的重要因素,在 HDFS 中,可以调整数据块的副本数量、存储策略等参数,以适应不同的负载需求,在 HBase 中,可以设置 Region 的大小、缓存策略等参数,来优化负载均衡效果。
还需要考虑到系统的扩展性,随着数据量的不断增长和业务需求的变化,负载均衡机制应该能够灵活地适应新的情况,确保系统始终保持高效运行。
实现 HDFS 和 HBase 的负载均衡是一个综合性的任务,需要从多个方面进行考虑和优化,只有通过不断的实践和探索,结合具体的业务场景和系统特点,才能构建出性能卓越、稳定可靠的大数据存储和处理系统。