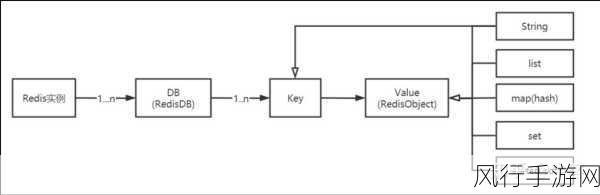
在 Ruby 编程中,正则表达式是强大的工具,但过度捕获可能会带来一些意想不到的问题,要有效地避免过度捕获,我们需要深入理解正则表达式的工作原理和一些实用的技巧。
在处理文本数据时,正则表达式的使用十分频繁,如果不加以注意,过度捕获可能导致性能下降、逻辑混乱以及不必要的资源消耗。

如何避免这种情况呢?
一种常见的方法是精确指定捕获组的范围和需求,只捕获真正需要的部分,避免过度宽泛的捕获,在匹配电子邮件地址时,如果只需要获取用户名部分,就不要将整个地址都进行捕获。
合理运用非捕获组也是关键,非捕获组可以执行匹配操作,但不会将匹配的结果进行捕获,通过使用(?:...) 这种形式,能够在不影响匹配结果的前提下,减少不必要的捕获。
对于复杂的匹配模式,要进行仔细的分析和规划,在设计正则表达式之前,先明确需要提取的信息以及其出现的规律,从而构建出更加简洁高效的表达式。
还需要注意的是,对正则表达式进行性能测试和优化,在实际应用中,通过对不同的表达式进行测试,观察其在处理大量数据时的表现,及时发现可能存在的过度捕获问题并进行调整。
避免 Ruby 正则表达式的过度捕获需要我们从多个方面入手,综合运用各种技巧和方法,只有这样,才能在保证匹配准确性的同时,提高程序的性能和效率,让我们的 Ruby 编程更加得心应手。