探索 Python3 爬虫在多语言网站处理中的潜力与挑战
在当今数字化的时代,互联网上的信息如浩瀚海洋般丰富多样,而多语言网站更是其中独特的存在,对于 Python3 能否有效地处理多语言网站是一个备受关注的问题。
Python3 作为一种强大而灵活的编程语言,为爬虫的开发提供了坚实的基础,多语言网站的特点在于其页面中包含了多种语言的文字、字符编码和特定的语言规则,这就给爬虫的处理带来了一定的复杂性。
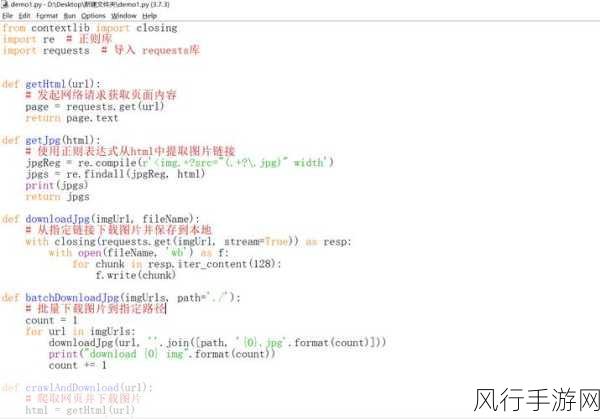
Python3 爬虫到底有没有能力应对多语言网站呢?答案是肯定的,但需要一系列的技术和策略支持。
其一,字符编码的处理至关重要,不同的语言可能使用不同的字符编码方式,UTF-8、GBK 等,Python3 提供了丰富的库和函数来处理字符编码的转换和识别,确保爬虫能够正确解析和提取多语言的文本内容。

其二,语言识别技术也是关键的一环,为了准确地处理多语言网站,爬虫需要能够识别页面中使用的语言,这可以通过分析页面的元数据、语言标记或者利用自然语言处理技术来实现。
其三,处理多语言网站还需要考虑到不同语言的语法和词汇特点,某些语言可能具有特定的语法结构和词汇规则,这可能会影响到爬虫对文本的理解和提取,在编写爬虫代码时,需要针对不同语言进行相应的优化和调整。
反爬虫机制也是在处理多语言网站时需要面对的挑战之一,许多网站为了保护自身的内容和服务,会设置各种反爬虫措施,对于多语言网站,这些反爬虫机制可能会更加复杂和严格,爬虫开发者需要不断探索和创新,采用合理的策略来规避反爬虫机制,确保爬虫的稳定运行。
Python3 爬虫在处理多语言网站方面具有很大的潜力,但也面临着诸多挑战,只有通过不断地学习和实践,掌握相关的技术和技巧,才能充分发挥 Python3 爬虫的优势,有效地获取多语言网站中的有价值信息,随着技术的不断发展和创新,相信 Python3 爬虫在处理多语言网站方面将会取得更加出色的成果。