探究 C 语言中 set 排序的神秘算法
在计算机编程领域,C 语言的应用广泛且重要,而其中的 set 排序算法一直是开发者们关注的焦点之一。
C 语言中的 set 排序并非简单的操作,它背后蕴含着精妙的算法逻辑,要理解其排序所基于的算法,我们需要先明确 set 的基本概念和特点。
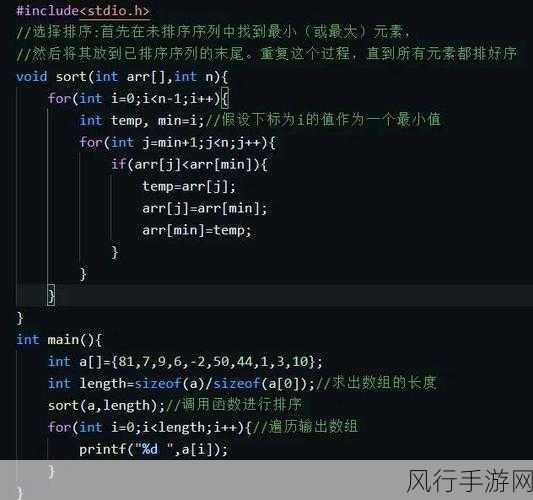
set 是一种数据结构,通常用于存储唯一的元素,并按照特定的顺序进行排列,在 C 语言中,实现 set 排序的常见算法有多种,其中较为常见的是快速排序算法。
快速排序是一种分治的排序算法,其基本思想是通过选择一个基准元素,将待排序的序列划分为两个子序列,其中一个子序列的所有元素都小于等于基准元素,另一个子序列的所有元素都大于等于基准元素,对这两个子序列分别进行快速排序,最终使整个序列有序。
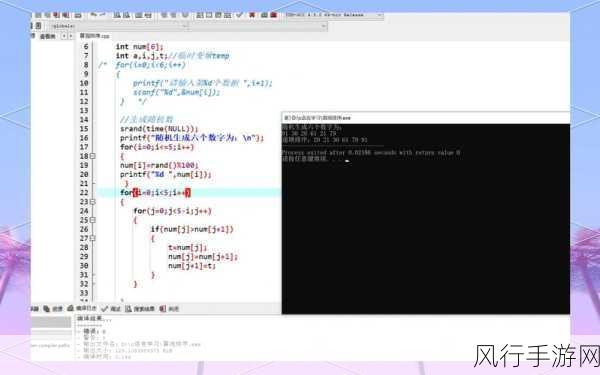
在 C 语言中使用快速排序算法对 set 进行排序,具有较高的效率,这是因为快速排序在平均情况下的时间复杂度为 O(nlogn),n 是待排序元素的数量,相比其他一些排序算法,如冒泡排序、插入排序等,快速排序在处理大规模数据时表现更为出色。
还有可能使用归并排序算法来实现 C 语言中 set 的排序,归并排序同样是一种分治算法,它将待排序的序列分成两个子序列,分别对这两个子序列进行排序,然后将排序后的两个子序列合并成一个有序的序列,归并排序的时间复杂度也为 O(nlogn),但在空间复杂度上可能会比快速排序略高。
无论是快速排序还是归并排序,它们在 C 语言中实现 set 排序时,都需要考虑元素的比较和交换操作,在实际编程中,还需要根据具体的应用场景和数据特点来选择最合适的排序算法,以达到最优的性能。
C 语言中 set 排序所基于的算法并非单一固定的,而是可以根据不同的需求和条件选择合适的高效算法,深入理解这些算法的原理和特点,对于提升 C 语言编程能力和优化程序性能具有重要意义。