深度剖析,SparkSQL 优化与数据准确性的紧密关联
在当今数字化时代,数据已成为企业决策的重要依据,要确保数据的准确性并非易事,这就需要我们深入研究和应用各种技术手段,SparkSQL 优化便是提升数据准确性的关键之一。
数据的准确性对于企业的运营和发展至关重要,不准确的数据可能导致错误的决策,进而给企业带来巨大的损失,而 SparkSQL 作为一种强大的数据处理工具,通过合理的优化能够有效地减少数据处理过程中的误差,提高数据的质量。
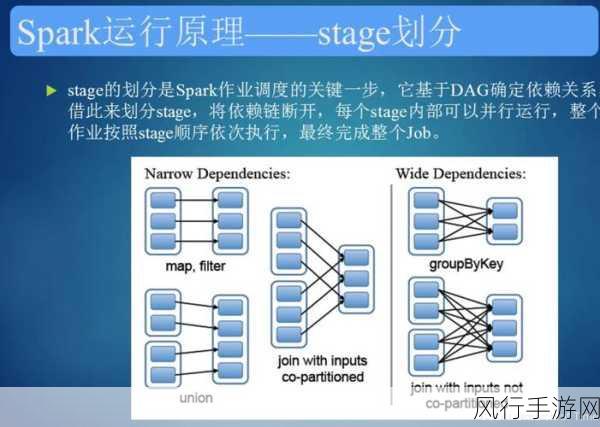
SparkSQL 优化究竟是如何增强数据准确性的呢?
其一,优化查询计划,SparkSQL 在执行查询时会生成一个查询计划,通过对这个计划进行优化,可以选择更高效的执行方式,减少数据处理中的冗余操作和错误,合理地选择索引、分区策略以及连接方式,能够大大提高查询的准确性和效率。
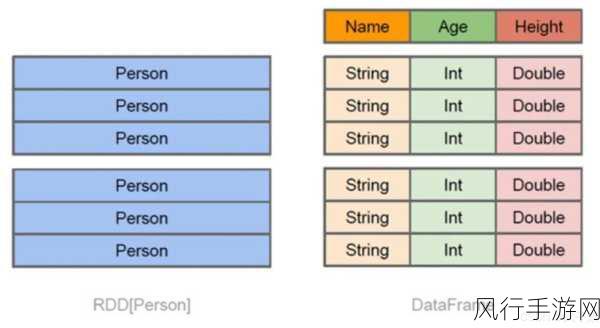
其二,数据清洗和预处理,在将数据输入到 SparkSQL 进行处理之前,进行有效的数据清洗和预处理工作是必不可少的,去除重复数据、纠正错误数据、处理缺失值等操作,可以从源头上保证数据的质量,从而为后续的准确分析奠定基础。
其三,监控和调试,在使用 SparkSQL 进行数据处理的过程中,持续的监控和调试是确保数据准确性的重要环节,及时发现并解决可能出现的错误,比如数据倾斜、内存溢出等问题,能够保证数据处理的正常进行,提高数据的准确性。
其四,优化数据存储,选择合适的数据存储格式和存储位置,能够提高数据的读取和写入效率,减少数据损坏和丢失的风险,进而增强数据的准确性。
团队协作和知识共享也是保障 SparkSQL 优化效果的重要因素,数据工程师、分析师和开发人员之间的密切合作,能够充分发挥各自的专业优势,共同解决在优化过程中遇到的问题。
SparkSQL 优化是一项复杂而系统的工作,需要综合考虑多个方面的因素,只有通过不断地学习和实践,掌握先进的优化技术和方法,才能充分发挥 SparkSQL 的优势,提高数据的准确性,为企业的发展提供有力的支持,在未来,随着数据量的不断增长和业务需求的日益复杂,SparkSQL 优化在保障数据准确性方面的作用将愈发重要,我们应持续关注和探索这一领域的发展。