探索语音识别开发的多元技术路径
语音识别技术作为人工智能领域的重要分支,正在以惊人的速度改变着我们与设备和系统的交互方式,从智能语音助手到语音转文字工具,其应用范围日益广泛,语音识别开发究竟有哪些技术路线呢?
要深入了解语音识别开发的技术路线,我们得先从信号处理的角度出发,在这一环节,对输入的语音信号进行预处理至关重要,通过降噪、端点检测等手段,去除噪声和无关部分,提取出有效的语音片段,为后续的特征提取和模式识别奠定基础。
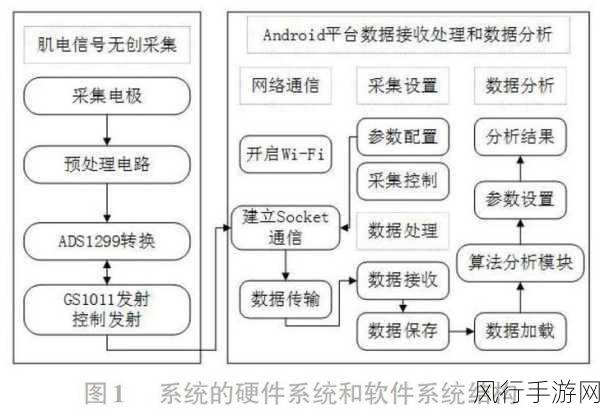
特征提取是关键的一步,常用的特征包括梅尔频率倒谱系数(MFCC)、感知线性预测(PLP)等,这些特征能够捕捉语音信号中的重要信息,如音高、时长、频率等,将复杂的语音信号转化为可用于模式识别的数值向量。
模式识别则是语音识别的核心部分,基于隐马尔可夫模型(HMM)的方法曾经占据主导地位,HMM 能够对语音的时序特征进行建模,通过计算观测序列与模型的匹配概率来识别语音,随着深度学习技术的崛起,深度神经网络(DNN)、循环神经网络(RNN)及其变体,如长短期记忆网络(LSTM)和门控循环单元(GRU)等,在语音识别中展现出了更强大的性能。
深度学习模型能够自动从大量的数据中学习到复杂的特征和模式,大大提高了语音识别的准确率,卷积神经网络(CNN)可以有效地提取语音信号的局部特征,而 RNN 系列网络则擅长处理序列数据,能够更好地捕捉语音的上下文信息。
为了进一步提高语音识别的性能,多模态融合的技术路线也逐渐受到关注,将语音与其他模态的信息,如唇语、面部表情等相结合,可以提供更多的线索和约束,从而提高识别的准确性和鲁棒性。
在实际的语音识别开发中,还需要考虑到语言模型的优化,语言模型用于预测语音所对应的文字序列的概率,通过引入更强大的语言模型,如基于神经网络的语言模型,可以更好地利用语言的语法、语义等知识,提高识别结果的合理性和准确性。
语音识别开发的技术路线丰富多样,不断地演进和创新,从传统的信号处理和模式识别方法到深度学习的广泛应用,再到多模态融合和语言模型的优化,每一次技术的突破都为语音识别带来了新的机遇和挑战,随着技术的不断进步,我们有理由相信语音识别将在更多领域发挥重要作用,为人们的生活和工作带来更大的便利。