探索 Hadoop 生态系统的关键组件
Hadoop 生态系统是大数据处理领域的重要基石,它由一系列相互协作的组件构成,共同为海量数据的存储、处理和分析提供了强大的支持。
Hadoop 生态系统中的核心组件之一是 Hadoop 分布式文件系统(HDFS),HDFS 是一种能够在大规模集群上可靠存储大量数据的分布式文件系统,它将数据分成多个块,并将这些块分布在不同的节点上,从而实现了数据的冗余存储和高可用性,这意味着即使某些节点出现故障,数据仍然可以被访问和恢复,确保了数据的安全性和可靠性。
另一个关键组件是 MapReduce 框架,MapReduce 是一种用于大规模数据处理的编程模型和计算框架,它将复杂的计算任务分解为两个阶段:Map 阶段和 Reduce 阶段,在 Map 阶段,数据被并行处理和转换;在 Reduce 阶段,对 Map 阶段的结果进行汇总和整合,通过这种方式,MapReduce 能够高效地处理海量数据,充分利用集群的计算资源。
除了 HDFS 和 MapReduce,Hadoop 生态系统还包括 Hive,Hive 是基于 Hadoop 的数据仓库工具,它提供了类似 SQL 的查询语言,使得不熟悉编程的用户也能够方便地对大规模数据进行查询和分析,Hive 将用户编写的 SQL 语句转换为 MapReduce 任务,在 Hadoop 集群上执行,从而实现了对大数据的快速处理和分析。

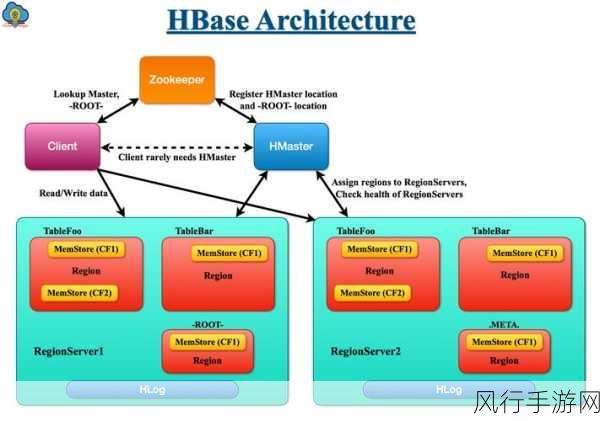
还有 HBase,这是一个分布式的、面向列的数据库,它适合于实时读写、随机访问大规模数据的场景,HBase 基于 HDFS 存储数据,提供了高并发的数据读写能力,并且能够自动扩展以适应不断增长的数据量。
Sqoop 也是 Hadoop 生态系统中的重要一员,Sqoop 用于在 Hadoop 和传统关系型数据库之间进行数据的导入和导出,实现了不同数据源之间的数据交换和集成。
Spark 也是不可忽视的组件,与 MapReduce 相比,Spark 在内存计算方面具有显著优势,能够大大提高数据处理的速度和效率。
Hadoop 生态系统的各个组件相互配合,为大数据处理提供了全面而强大的解决方案,从数据存储到计算处理,从数据分析到数据交换,每个组件都发挥着独特的作用,共同推动着大数据技术的发展和应用,随着数据量的不断增长和数据处理需求的日益复杂,深入了解和掌握 Hadoop 生态系统的组件将变得越来越重要,为企业和组织在大数据时代中获取有价值的信息和洞察提供有力支持。