深入探究 HBase 数据类型与反序列化的奥秘
HBase 作为一种分布式的大数据存储系统,在处理海量数据方面表现出色,其数据类型和反序列化机制是实现高效数据存储与访问的关键组成部分。
HBase 中的数据类型丰富多样,能够满足各种复杂的数据存储需求,常见的数据类型包括字节数组(Byte Array)、字符串(String)、整数(Integer)、长整数(Long)、浮点数(Float)和双精度浮点数(Double)等,这些基本数据类型为数据的表示和存储提供了基础。

字节数组是 HBase 中最灵活的数据类型之一,可以用来存储任意二进制数据,字符串类型则常用于存储文本信息,方便进行文本的检索和处理,整数和长整数类型适用于存储数值型数据,如计数、标识符等,浮点数和双精度浮点数则用于处理带有小数部分的数值。
而反序列化在 HBase 中起着至关重要的作用,当从 HBase 中读取数据时,需要将存储的二进制数据转换为应用程序能够理解和处理的格式,这就是反序列化的过程。
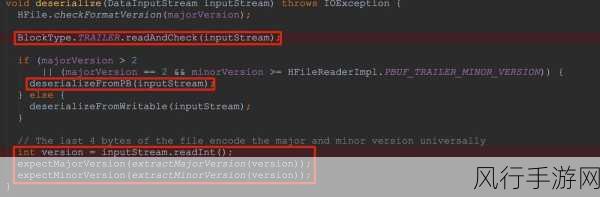
HBase 的反序列化机制通常基于特定的序列化框架和算法,这些框架和算法能够高效地将二进制数据转换为相应的数据类型,并确保数据的准确性和完整性,在反序列化过程中,需要考虑数据的编码方式、字段的顺序和长度等因素,以正确地还原数据的原始结构和内容。
为了提高反序列化的性能,通常会采用一些优化策略,使用缓存机制来存储常用的反序列化结果,避免重复计算,合理选择序列化和反序列化的算法,根据数据的特点和访问模式进行调整,以达到最佳的性能效果。
在实际应用中,还需要处理数据类型的兼容性和版本控制问题,当 HBase 中的数据结构发生变化时,需要确保新的版本能够正确地读取和处理旧版本的数据,同时也要保证旧版本的应用程序能够与新版本的数据兼容。
深入理解 HBase 的数据类型和反序列化机制对于充分发挥 HBase 的性能和优势至关重要,通过合理选择数据类型、优化反序列化过程以及处理好相关的兼容性问题,能够构建出高效、可靠的大数据存储和处理系统,满足日益增长的业务需求。