探索 Hadoop 分布式数据库的扩展之道
在当今数字化时代,数据量呈现爆炸式增长,企业对于数据处理和存储的需求也日益提高,Hadoop 分布式数据库作为一种强大的数据处理和存储解决方案,其扩展能力成为了关键,如何有效地扩展 Hadoop 分布式数据库呢?
Hadoop 分布式数据库的扩展并非一蹴而就,它涉及到多个方面的考量和技术的综合运用,从硬件资源的扩充到软件架构的优化,每一个环节都至关重要。
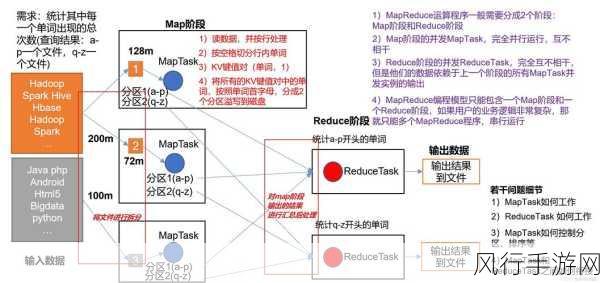
在硬件层面,增加节点数量是常见的扩展方式,通过向集群中添加更多的服务器节点,可以提升整体的存储和计算能力,但这并非简单地插上新的服务器就行,还需要考虑网络带宽、存储容量以及服务器的性能匹配等因素,如果新加入的节点性能过强或过弱,都可能导致整个集群的性能失衡。
软件方面,对 Hadoop 配置参数的调整也能影响其扩展性,合理设置数据块的大小、副本数量以及任务的并行度等,这些参数的优化需要根据实际的数据特点和业务需求进行精细的调整,以达到最佳的扩展效果。
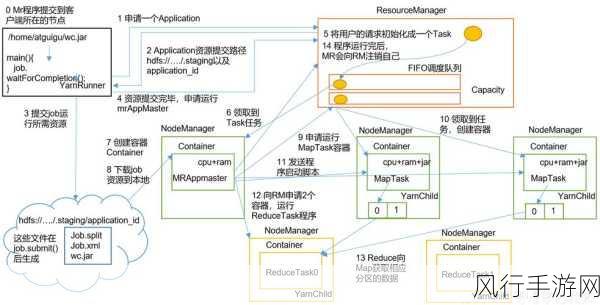
数据的分布策略也对扩展有着重要影响,Hadoop 通常采用分布式存储数据,如何确保数据在新增节点时能够均匀分布,避免出现数据倾斜的情况,是需要重点关注的问题,数据倾斜会导致部分节点负载过高,影响整个集群的性能和扩展性。
在扩展过程中,还需要考虑数据的一致性和可靠性,Hadoop 采用了一系列的机制来保证数据的完整性和可用性,但在扩展时可能会引入新的风险,需要对数据的备份、恢复以及错误处理等方面进行充分的规划和测试。
对于 Hadoop 分布式数据库的扩展,还需要结合业务的发展进行前瞻性的规划,预测未来的数据增长趋势和业务需求的变化,提前做好架构的调整和资源的准备,避免在业务高峰期出现性能瓶颈。
Hadoop 分布式数据库的扩展是一个综合性的工程,需要从硬件、软件、数据管理以及业务规划等多个角度进行全面的考虑和优化,只有这样,才能充分发挥 Hadoop 分布式数据库的优势,满足不断增长的业务需求。