提升 Spark 部署性能的关键策略与实践
Spark 作为大数据处理领域的强大工具,其部署性能的保障至关重要,在当今数据驱动的时代,企业和组织对数据处理的速度和效率有着越来越高的要求,有效的 Spark 部署性能保障不仅能够提高数据处理的效率,还能节省资源成本,提升整体业务的竞争力。
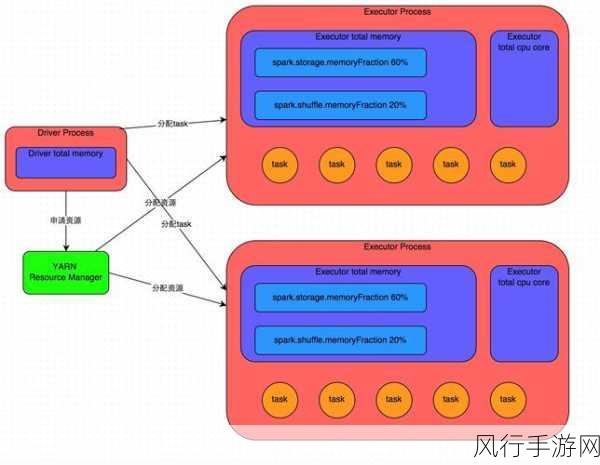
要保障 Spark 部署性能,合理的资源配置是基础,这包括对内存、CPU 核心数、磁盘 I/O 等资源的精确分配,如果内存配置不足,可能会导致频繁的内存交换,从而严重影响性能;而 CPU 核心数配置不当,则可能无法充分发挥 Spark 并行处理的优势,在资源配置时,需要充分考虑业务的实际需求和数据量的大小。
优化数据存储和读取方式也是提升性能的重要环节,选择合适的数据格式,如 Parquet 或 ORC,可以提高数据的压缩比和读取效率,对数据进行分区和索引,可以减少数据扫描的范围,加快数据查询和处理的速度。
调整 Spark 的配置参数同样不可或缺,调整 spark.executor.memory、spark.sql.shuffle.partitions 等参数,可以根据实际的硬件环境和业务场景进行优化,但需要注意的是,参数的调整需要经过充分的测试和验证,避免因不当的配置导致性能下降。
对于 Spark 任务的执行计划,进行优化也是关键的一步,通过分析任务的逻辑和数据流程,合理地选择使用合适的算子和算法,可以显著提高性能,在某些场景下,使用广播变量可以避免数据的重复传输,提高任务执行效率。
网络环境的稳定性和带宽也会对 Spark 部署性能产生影响,确保网络的低延迟和高带宽,能够减少数据传输的时间开销,提升数据处理的整体速度。
持续的性能监控和优化是保障 Spark 部署性能的长效机制,通过监控关键指标,如任务执行时间、资源利用率等,及时发现性能瓶颈,并采取相应的优化措施,使 Spark 部署性能始终保持在良好的水平。
保障 Spark 部署性能是一个综合性的工作,需要从资源配置、数据存储、参数调整、任务优化、网络环境以及性能监控等多个方面入手,不断探索和实践,才能充分发挥 Spark 的强大性能,为企业和组织的数据处理业务提供有力支持。