探索 Python 机器学习库处理大规模数据的卓越之道
在当今数字化时代,数据的规模呈爆炸式增长,如何有效地处理大规模数据成为了众多领域面临的关键挑战,而 Python 机器学习库凭借其强大的功能和灵活的特性,为我们提供了有效的解决方案。
Python 拥有众多优秀的机器学习库,如 TensorFlow、PyTorch、Scikit-learn 等,它们在处理大规模数据方面各有优势,以 TensorFlow 为例,其分布式计算能力使得可以在多台机器上并行处理数据,大大提高了处理速度和效率。
处理大规模数据时,数据预处理是至关重要的一环,数据可能存在缺失值、异常值、重复数据等问题,需要进行清洗和转换,可以使用 Python 的 Pandas 库对数据进行读取、筛选、填充缺失值等操作,为后续的机器学习任务提供高质量的数据。
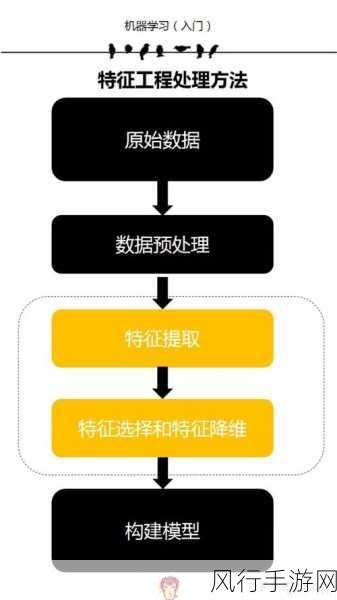
特征工程也是处理大规模数据中的重要步骤,通过从原始数据中提取有意义的特征,可以更好地表示数据,提高模型的性能,Python 中的 Featuretools 库可以自动进行特征生成和选择,帮助我们发现数据中的隐藏模式和关系。

在模型训练方面,选择合适的算法和架构对于处理大规模数据至关重要,深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)在处理图像、文本等大规模数据时表现出色,通过调整模型的超参数,如学习率、层数、节点数等,可以优化模型的性能。
为了应对大规模数据的训练需求,还可以采用随机梯度下降(SGD)的变体,如 Adagrad、Adadelta 等优化算法,它们能够根据数据的特点自适应地调整学习率,加快收敛速度。
模型评估也是不可或缺的环节,在处理大规模数据时,需要使用合适的评估指标来衡量模型的性能,如准确率、召回率、F1 值等,通过交叉验证等技术,可以更准确地评估模型的泛化能力。
在实际应用中,还需要考虑模型的部署和优化,将训练好的模型部署到生产环境中,需要考虑性能、资源消耗等因素,可以采用模型压缩、量化等技术来减少模型的大小和计算量,提高运行效率。
Python 机器学习库为处理大规模数据提供了丰富的工具和方法,通过合理运用数据预处理、特征工程、模型选择和优化、评估和部署等技术,我们能够充分挖掘大规模数据的价值,为解决各种实际问题提供有力支持,在未来,随着技术的不断发展和创新,Python 机器学习库在处理大规模数据方面将发挥更加重要的作用,为推动人工智能和数据科学的进步做出更大的贡献。