探索 Python 网络爬虫的优质框架
在当今数字化信息时代,网络爬虫成为了获取大量数据的重要手段,对于从事数据采集和分析的开发者来说,选择一个合适的 Python 网络爬虫框架至关重要。
Python 拥有众多出色的爬虫框架,每个框架都有其独特的特点和优势,Scrapy 框架无疑是其中的佼佼者,它是一个功能强大、高度灵活且易于扩展的框架,Scrapy 框架提供了丰富的功能,包括强大的页面解析机制、高效的请求调度、数据处理和存储等,使用 Scrapy 框架,开发者可以轻松地构建复杂的爬虫项目,应对各种网站的爬取需求。
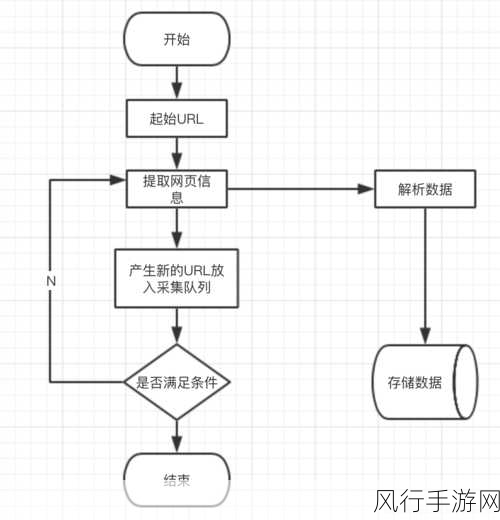
另一个值得一提的框架是 PySpider,PySpider 具有简洁直观的界面和易于上手的特点,它提供了可视化的操作界面,方便开发者对爬虫任务进行监控和管理,PySpider 支持多种数据存储方式,如 MySQL、MongoDB 等,能够满足不同场景下的数据存储需求。
还有一个备受关注的框架是 requests + BeautifulSoup 组合,requests 库用于发送 HTTP 请求,获取网页内容,而 BeautifulSoup 则用于解析 HTML 和 XML 文档,这个组合虽然相对简单,但对于一些小型的爬虫项目或者对性能要求不是特别高的场景,是一个非常实用的选择。
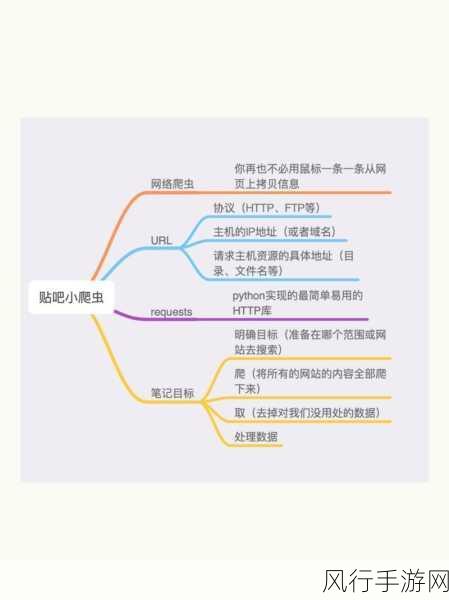
那么在实际应用中,如何选择适合自己的框架呢?这需要根据具体的需求和项目规模来决定,如果是大型、复杂的爬虫项目,对性能和扩展性要求较高,Scrapy 框架可能是最佳选择,而对于小型、快速开发的项目,或者对可视化操作有需求的开发者,PySpider 或者 requests + BeautifulSoup 组合则更为合适。
Python 网络爬虫框架众多,各有千秋,开发者需要根据自身的实际情况和项目需求,选择最适合自己的框架,以便高效、准确地获取所需的数据,为后续的数据分析和应用打下坚实的基础,在探索和选择的过程中,不断学习和实践,才能更好地掌握网络爬虫技术,为数据驱动的业务和研究提供有力支持。