SQL Server 索引与大数据处理的深度探讨
在当今数字化时代,数据的规模和复杂性呈爆炸式增长,大数据处理成为了众多企业和组织面临的重要挑战,而在数据库管理中,SQL Server 作为广泛应用的关系型数据库系统,其索引机制在处理大数据时的表现备受关注,SQL Server 索引能否有效地应对大数据的处理需求呢?
SQL Server 索引是一种用于加速数据检索和查询操作的数据结构,它通过对表中的列创建索引,使得数据库能够更快地定位和获取所需的数据,在大数据环境下,索引的有效性并非简单的是或否的答案。
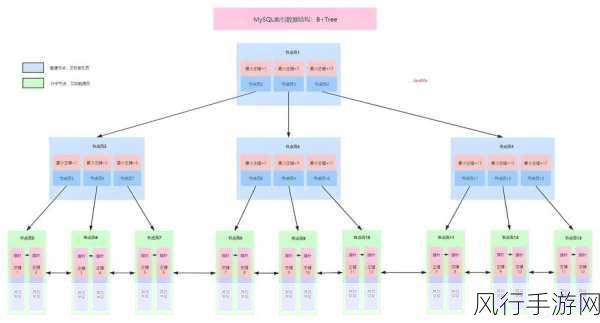
大数据的特点通常包括海量的数据量、多样的数据类型和高速的数据生成速度,对于 SQL Server 处理如此大规模的数据需要考虑多个因素,首先是索引的类型选择,SQL Server 提供了多种索引类型,如聚集索引、非聚集索引、唯一索引等,在大数据场景中,正确选择适合数据特点和查询需求的索引类型至关重要,对于经常用于范围查询的列,非聚集索引可能更为合适;而对于需要保证数据唯一性的列,唯一索引则是必要的。
索引的维护成本也是一个关键问题,在大数据量的情况下,插入、更新和删除操作可能会导致索引的频繁更新,从而增加系统的开销,需要在索引带来的查询性能提升和维护成本之间进行权衡。
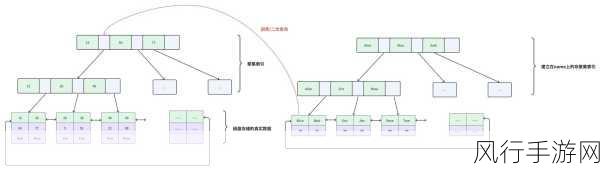
大数据处理往往涉及复杂的查询和关联操作,SQL Server 索引在处理简单的单表查询时表现出色,但在处理多表关联和复杂的数据分析任务时,可能需要结合其他技术和策略,如分区表、索引视图等,以提高整体性能。
硬件资源的配置也对 SQL Server 索引处理大数据的能力产生影响,充足的内存、高速的存储设备和强大的 CPU 处理能力能够为索引的有效运行提供支持。
SQL Server 索引在处理大数据时具有一定的能力,但需要综合考虑数据特点、查询需求、索引类型选择、维护成本、硬件配置等多方面因素,通过合理的设计和优化,SQL Server 索引可以在大数据处理中发挥重要作用,提高数据检索和查询的效率,为企业和组织的业务决策提供有力支持。
也要认识到,对于极端大规模和复杂的大数据处理需求,可能需要结合其他更专门的大数据技术和框架,如 Hadoop 生态系统等,但在许多中大规模的企业应用场景中,SQL Server 索引仍然是不可或缺的重要工具,只要运用得当,就能在大数据的海洋中为用户快速准确地找到所需的信息宝藏。
SQL Server 索引在大数据处理领域既有潜力可挖,也面临挑战,不断的实践、探索和优化是充分发挥其效能的关键所在。