Cassandra 数据一致性故障恢复,速度与效率的深度剖析
Cassandra 作为一款广受欢迎的分布式数据库,在处理大规模数据方面表现出色,当面临数据一致性故障时,其恢复速度一直是用户关注的焦点。
Cassandra 采用了分布式架构,这意味着数据分布在多个节点上,这种架构在提供高可用性和可扩展性的同时,也为数据一致性故障的恢复带来了一定的挑战,在数据一致性出现问题时,Cassandra 需要协调多个节点之间的信息,以确保数据的准确和完整恢复。
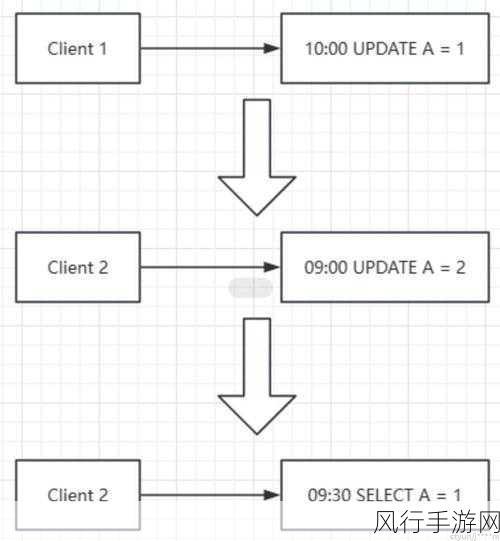
Cassandra 具备一系列机制来应对数据一致性故障,副本机制起着关键作用,通过在不同节点上保存数据的多个副本,当一个节点出现故障或数据不一致时,可以从其他正常的副本中获取正确的数据进行恢复,Cassandra 的 gossip 协议有助于节点之间快速传播信息,使得系统能够及时感知到数据一致性问题,并启动恢复流程。
不过,Cassandra 数据一致性故障恢复的速度并非单纯取决于其自身的技术架构和机制,实际的恢复速度还受到多种因素的影响,网络环境的稳定性和带宽大小直接关系到数据传输的效率,如果网络存在延迟或丢包,恢复过程可能会受到明显的阻碍。
数据量的大小也是一个重要因素,当面临大规模的数据一致性故障时,需要处理和恢复的数据量巨大,这必然会增加恢复的时间和复杂性,系统的负载情况也会对恢复速度产生影响,如果在恢复过程中,系统仍然承受着较高的并发访问和写入请求,那么资源的竞争可能会导致恢复速度的下降。
为了提高 Cassandra 数据一致性故障恢复的速度,可以采取一些优化措施,优化网络基础设施,确保稳定和高速的网络连接,合理规划数据分布和副本策略,减少数据恢复时的处理量。
Cassandra 数据一致性故障恢复的速度是一个相对复杂的问题,受到多种因素的综合影响,虽然它具备有效的恢复机制,但在实际应用中,需要充分考虑系统的配置、环境和数据特点,以实现更快速和可靠的数据恢复。