SparkSQL 作为大数据处理领域的重要工具,其优化策略在不同的数据处理场景中发挥着关键作用,在当今数据驱动的时代,高效处理和分析海量数据成为企业和组织获取竞争优势的关键,了解 SparkSQL 优化适用的具体数据处理场景,对于提升数据处理效率和质量具有重要意义。
SparkSQL 优化在处理大规模结构化数据时表现出色,当面对金融交易数据、电商销售数据等具有明确结构和大量记录的数据集时,通过合理的索引创建、分区策略以及缓存设置,可以显著提高查询性能,这些优化手段能够减少数据扫描量,快速定位所需数据,从而加快处理速度,满足对实时性要求较高的业务需求。
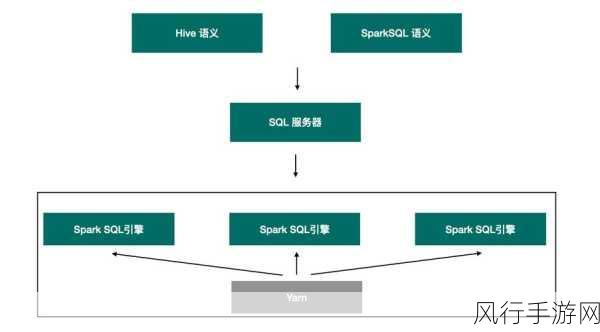
在处理复杂的关联操作场景中,SparkSQL 优化也能大显身手,当数据需要在多个表之间进行复杂的关联计算时,优化器能够根据数据分布和表结构等信息,选择最优的关联算法和执行计划,对关联条件的合理设置以及数据的预聚合处理,都有助于减少计算量和中间结果的生成,提高关联操作的效率。
对于频繁执行的查询任务,SparkSQL 的优化更是至关重要,通过对查询语句的重写和优化,以及利用持久化视图或物化视图,可以避免重复计算,提高查询的复用性,这在数据仓库和数据分析场景中尤为常见,能够大大节省计算资源和时间成本。
在处理数据倾斜的情况下,SparkSQL 优化也能提供有效的解决方案,数据倾斜是指某些键值在数据分布中出现频率过高,导致部分任务处理时间过长,通过识别和解决数据倾斜问题,如使用合适的分区方式、调整数据分布或者采用特定的算法进行处理,可以使任务在各个节点上更加均衡地执行,提高整体处理效率。
SparkSQL 优化适用于多种数据处理场景,从大规模结构化数据的处理到复杂关联操作,从频繁执行的查询到解决数据倾斜问题,掌握和应用这些优化策略,能够让数据处理工作更加高效、准确,为企业和组织的决策提供有力支持,在不断变化的数据处理需求中,持续探索和创新 SparkSQL 的优化方法,将是提升数据价值和竞争力的重要途径。