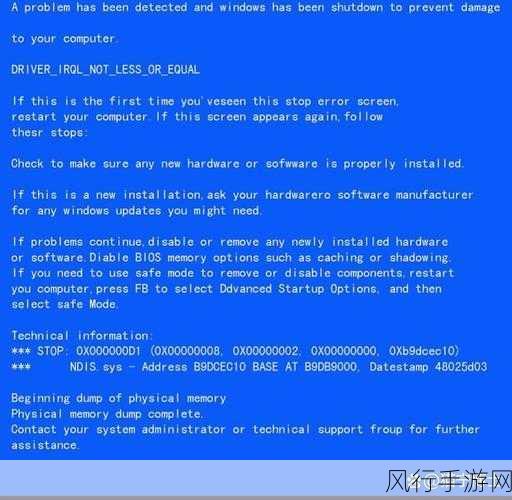
在当今数字化的时代,数据成为了宝贵的资源,Python 爬虫框架作为获取数据的有效工具,却常常面临反爬机制的挑战,如何应对这些反爬措施,成为了爬虫开发者们必须要攻克的难题。
我们要清楚地认识到,反爬机制的存在是为了保护网站的正常运营和数据的合法使用,常见的反爬手段包括 IP 封禁、验证码验证、请求频率限制等,而 Python 爬虫框架想要突破这些限制,就需要采取一系列巧妙的策略。

设置合理的请求头是关键的一步,通过模拟真实用户的浏览器请求头信息,包括 User-Agent、Referer 等,可以在一定程度上降低被识别为爬虫的概率,使用随机的 User-Agent 能够增加爬虫的伪装性,减少被反爬机制识破的风险。
控制请求频率至关重要,过于频繁的请求很容易被网站察觉并触发反爬机制,需要根据网站的实际情况,合理设置请求的间隔时间,可以通过引入随机延迟,使得请求的发送更加自然,仿佛是真实用户的行为。

处理验证码也是一个棘手但必须面对的问题,对于简单的验证码,可以使用 OCR 技术进行识别,而对于复杂的验证码,可能需要借助人工打码平台或者利用机器学习算法进行训练和识别。
IP 代理的运用是应对 IP 封禁的有效手段,通过使用大量的代理 IP,不断切换请求的 IP 地址,能够避免因为单个 IP 频繁请求而被封禁,但要注意选择稳定、高速的代理服务,以保证爬虫的效率和稳定性。
对于一些需要登录才能获取数据的网站,模拟登录过程是必不可少的,分析网站的登录接口和参数,正确提交登录信息,获取有效的登录凭证,从而能够访问更多受限制的页面和数据。
在应对反爬机制的过程中,还需要不断地监测和分析爬虫的运行情况,及时发现被封禁或者受到限制的迹象,调整策略和参数,以适应网站的变化。
Python 爬虫框架与反爬机制之间的斗争是一场持续的博弈,只有不断地探索和创新,灵活运用各种技术和策略,才能在合法合规的前提下,获取到所需的数据资源,也要遵守相关的法律法规和道德规范,确保爬虫行为不会对网站和用户造成不良影响。