Kafka 作为一种高性能的分布式消息队列系统,在大数据处理和实时数据传输中发挥着重要作用,数据积压问题可能会影响系统的性能和稳定性,进而影响业务的正常运行,解决数据积压问题并提升消费能力成为了许多开发者和运维人员关注的焦点。
要有效地处理 Kafka 数据积压并提升消费能力,我们需要从多个方面进行考虑和优化。
从数据生产端入手,要确保数据的生成速率合理且稳定,避免出现短时间内大量数据涌入 Kafka 而导致的积压,这需要对数据的来源和生成机制进行深入分析,可能需要调整数据采集的频率、批量大小或者采用更智能的限流策略。
在数据存储方面,合理配置 Kafka 的分区数量和副本因子至关重要,分区数量过少可能导致数据分布不均衡,影响消费效率;而副本因子过高则会增加存储成本和网络开销,通过对业务场景和数据量的评估,找到最适合的分区和副本配置,能够提升数据的存储和传输性能。
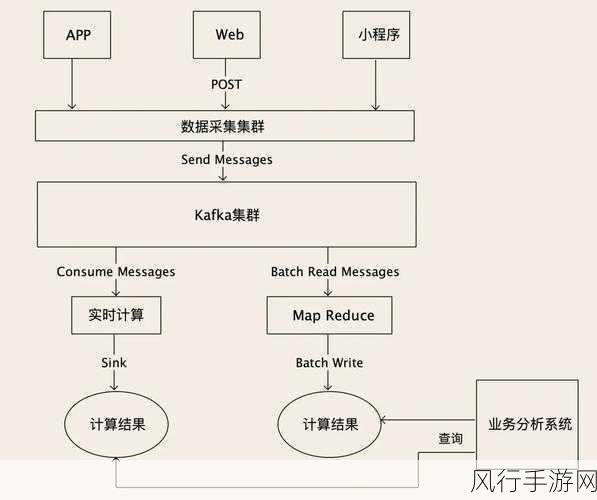
对于消费者端,优化消费逻辑是提升消费能力的核心,消费者在处理数据时,应避免复杂且耗时的操作,尽量采用高效的算法和数据结构,根据业务需求合理调整消费者的并发度和拉取数据的频率,以充分利用系统资源,提高消费效率。
监控和告警机制也是不可或缺的一部分,通过实时监控 Kafka 的各项指标,如消息堆积量、消费速率、分区负载等,能够及时发现潜在的数据积压问题,并触发告警通知相关人员进行处理,这样可以在问题恶化之前采取有效的措施,保障系统的稳定运行。
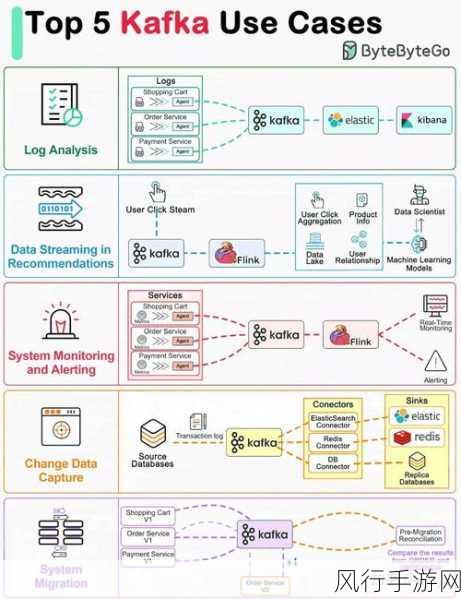
还可以考虑采用一些高级的技术手段,如使用 Kafka Streams 进行实时数据处理和转换,或者结合其他大数据处理框架,如 Flink,来实现更复杂的数据处理逻辑和更高效的消费能力。
处理 Kafka 数据积压并提升消费能力是一个综合性的任务,需要从数据生产、存储、消费以及监控等多个环节进行优化和改进,只有不断地实践和探索,结合具体的业务场景和需求,才能找到最适合的解决方案,确保 Kafka 系统在数据处理中发挥出最佳性能。