在当今数据驱动的时代,数据清洗成为了数据分析和处理中至关重要的环节,有效的数据清洗能够提高数据质量,为后续的分析和建模工作奠定坚实基础,Python 作为一种强大的编程语言,在数据清洗方面有着丰富的库和工具,如何优化 Python 数据清洗步骤,以提高效率和准确性,是许多数据从业者面临的挑战。
要优化 Python 数据清洗步骤,我们需要从多个方面入手,其中一个关键的方面是对数据的理解和分析,在开始清洗数据之前,深入了解数据的特点、结构以及可能存在的问题是非常重要的,通过对数据的初步观察和探索,我们可以确定需要处理的异常值、缺失值、重复值等情况,并制定相应的清洗策略。

合理选择和运用 Python 中的数据清洗库和函数也是优化的重要环节,pandas 库提供了丰富的方法来处理数据,如 fillna 函数用于填充缺失值,drop_duplicates 函数用于去除重复行,熟练掌握这些函数的使用技巧,并根据实际数据情况进行灵活运用,可以大大提高清洗效率。
优化数据清洗的代码结构也是不可忽视的,采用简洁、清晰的代码逻辑,将复杂的清洗任务分解为多个小的函数或模块,有助于提高代码的可读性和可维护性,合理使用循环和条件判断,避免不必要的重复计算和错误处理,能够进一步提升清洗性能。
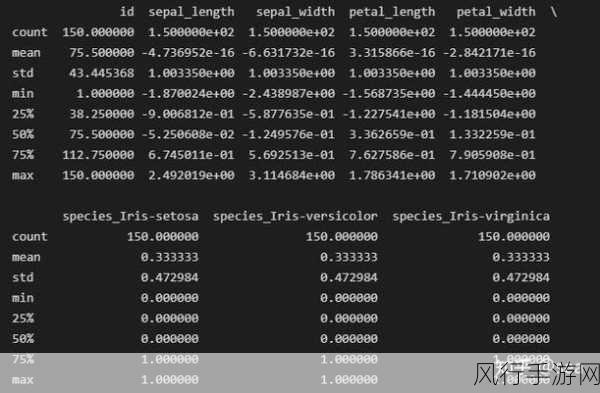
在数据量较大的情况下,考虑使用并行处理或分布式计算框架也是一个不错的选择,Dask 库可以在 Python 中实现并行计算,加快数据处理的速度。
对清洗后的结果进行验证和评估也是至关重要的,确保清洗后的数据符合预期的质量标准,并且没有引入新的错误或偏差。
优化 Python 数据清洗步骤需要综合考虑数据特点、库的选择、代码结构、并行处理以及结果验证等多个方面,通过不断的实践和探索,我们能够找到最适合具体数据和任务的优化方案,从而更高效地完成数据清洗工作,为数据分析和决策提供可靠的数据支持。