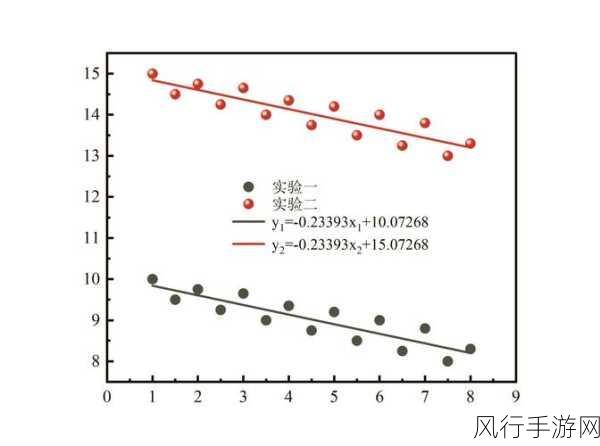
Cassandra 分布式存储系统在当今的大数据处理领域中发挥着重要作用,其卓越的读写性能是众多企业和开发者青睐的关键因素。
Cassandra 之所以能够实现出色的读写性能,关键在于其独特的架构设计和优化策略,从数据存储的角度来看,Cassandra 采用了分布式的列式存储方式,这种方式将数据按照列进行组织和存储,与传统的行式存储相比,大大减少了数据读取时的 I/O 开销,当我们需要查询特定列的数据时,无需读取整行数据,从而显著提高了读取效率。

在数据分布方面,Cassandra 利用一致性哈希算法将数据均匀地分布在多个节点上,这样的分布策略确保了数据的均衡存储,避免了某些节点负载过重而影响整体性能,当系统进行扩容或节点故障时,一致性哈希算法能够实现高效的数据迁移和重新分布,减少了对系统正常运行的干扰。
为了进一步提升读写性能,Cassandra 还采用了缓存机制,无论是在内存中设置数据缓存,还是在客户端进行预读缓存,都有效地减少了对磁盘的访问次数,缓存命中时,数据能够快速返回,极大地缩短了响应时间。
Cassandra 支持异步写入和批量写入操作,异步写入允许系统在后台处理写入请求,不会阻塞前端的应用程序,从而提高了写入的并发处理能力,批量写入则将多个小的写入请求合并为一个大的请求,减少了网络开销和系统调用的次数,进一步优化了写入性能。
在优化读写性能的过程中,Cassandra 对于数据压缩也给予了高度重视,通过有效的数据压缩算法,减少了数据在磁盘和网络中的传输量,不仅节省了存储空间,还提高了数据传输的效率。
除此之外,Cassandra 还具备强大的索引机制,合适的索引设计能够加速数据的查询操作,让系统更快地定位到所需的数据。
Cassandra 分布式存储通过一系列创新的技术和策略,不断提升其读写性能,为处理大规模数据提供了可靠且高效的解决方案,无论是在互联网应用、金融领域还是其他对数据处理性能有高要求的场景中,Cassandra 都展现出了卓越的优势,成为了分布式存储领域的佼佼者,要充分发挥 Cassandra 的性能优势,还需要根据具体的业务需求和应用场景进行合理的配置和优化,以确保其能够最大程度地满足实际应用的要求。