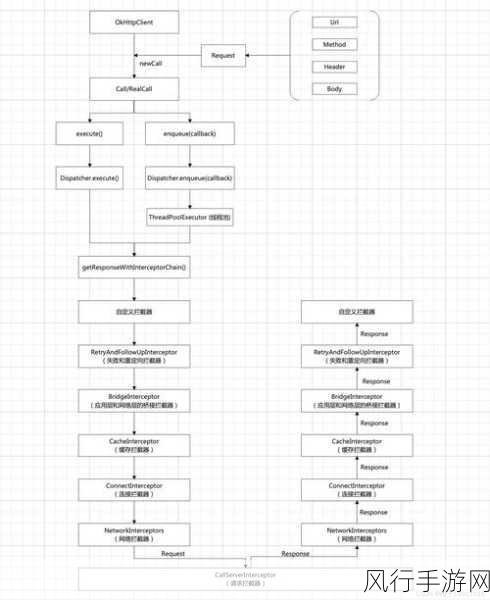
在当今数字化时代,数据处理成为了各个领域至关重要的环节,而 C# 作为一种广泛应用的编程语言,其提供的各种功能和方法对于高效处理数据起着关键作用,DistinctBy 方法在数据预处理中备受关注,那么它能否真正优化数据预处理呢?
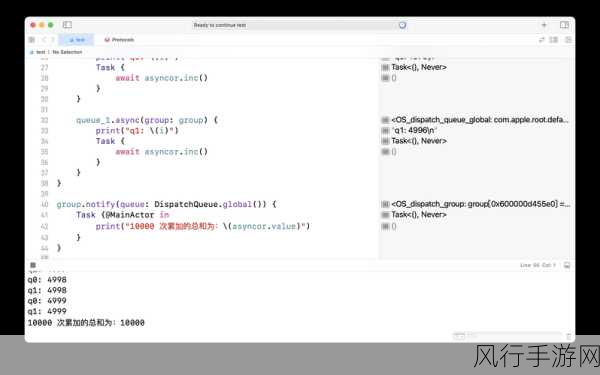
C# 中的 DistinctBy 方法旨在从一系列元素中根据指定的键选择唯一的元素,这在处理大量数据时,有可能减少重复数据,提高数据处理的效率,但要确定它是否能优化数据预处理,不能简单地一概而论,而是需要综合考虑多个因素。
从功能角度来看,DistinctBy 方法通过提取每个元素的特定属性作为键,然后基于这些键来确定唯一性,这在某些场景下,能够有效地避免对整个数据对象进行复杂的比较操作,从而节省计算资源和时间。
在实际应用中,其优化效果取决于数据的特点和规模,如果数据量较小,使用 DistinctBy 方法可能并不会带来显著的性能提升,甚至可能由于方法的调用和内部处理机制,导致额外的开销,但当面对大规模数据,且数据中的重复项较多时,DistinctBy 方法的优势就可能凸显出来。
还需要考虑数据的分布和复杂性,如果数据的键提取过程本身就非常复杂或者耗时,DistinctBy 方法带来的优化可能会被这部分额外的工作所抵消。
系统的硬件资源和运行环境也会对 DistinctBy 方法的优化效果产生影响,在资源充足的情况下,其性能表现可能相对较好;但在资源受限的环境中,可能需要更加谨慎地评估和使用。
C# 的 DistinctBy 方法在数据预处理中具有一定的优化潜力,但不能盲目地认为它在所有情况下都能带来显著的提升,在实际应用中,需要根据具体的数据特点、规模、分布以及运行环境等多方面因素进行综合评估和测试,以确定其是否真正适合用于优化数据预处理过程,从而实现更高效、准确的数据处理,只有经过充分的实践和分析,才能充分发挥 C# 语言提供的各种工具和方法的优势,为数据处理工作带来更好的效果和效率。