在大数据处理领域,Flink 作为一款强大的流处理框架,其窗口函数在时间聚合方面发挥着至关重要的作用,窗口函数能够将无界的数据流按照特定的规则进行切分和分组,从而实现对数据的高效处理和分析。
究竟 Flink 窗口函数是如何实现时间聚合的呢?这需要我们深入了解 Flink 窗口函数的工作原理和相关机制。
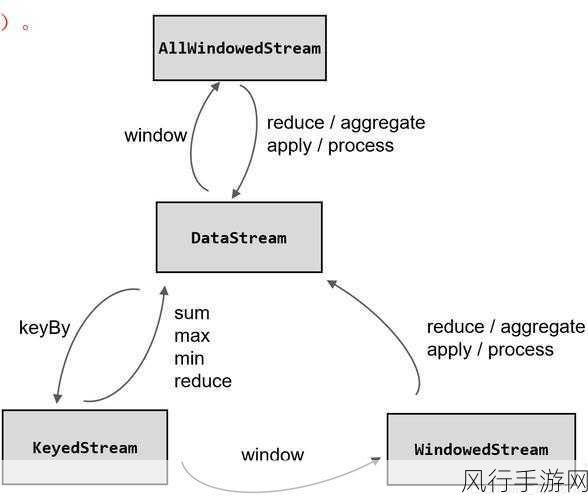
Flink 提供了多种类型的窗口,包括滚动窗口、滑动窗口、会话窗口等,滚动窗口是基于固定的时间间隔对数据进行切分,每个窗口之间互不重叠,设定一个 5 分钟的滚动窗口,那么每 5 分钟就会形成一个新的窗口,窗口内的数据会进行相应的聚合计算。
滑动窗口则与滚动窗口有所不同,它在时间上存在重叠部分,通过设置窗口大小和滑动步长,可以灵活地控制数据的聚合范围和频率,假设窗口大小为 10 分钟,滑动步长为 5 分钟,那么每 5 分钟就会有一个新的窗口产生,并且窗口之间会有 5 分钟的数据重叠。
会话窗口则是根据数据之间的间隔来划分窗口,当数据之间的间隔超过设定的时间阈值时,就会开启一个新的会话窗口。
在实现时间聚合时,还需要定义聚合函数,常见的聚合函数包括求和、平均值、计数、最大值、最小值等,通过将这些聚合函数应用到窗口内的数据上,可以得到我们所需要的统计结果。
为了确保窗口函数的正确运行,还需要对数据的时间戳进行准确的处理,Flink 支持从事件时间和处理时间两种方式来定义时间属性,事件时间是基于数据本身携带的时间戳,而处理时间则是基于 Flink 处理数据的系统时间。
Flink 窗口函数的时间聚合功能为大数据流处理提供了强大而灵活的工具,通过合理地选择窗口类型、定义聚合函数以及处理时间戳,我们能够从海量的数据流中快速提取有价值的信息,为各种业务需求提供有力支持,在实际应用中,需要根据具体的业务场景和数据特点,精心设计和优化窗口函数的参数,以达到最佳的处理效果和性能,只有深入理解和熟练掌握 Flink 窗口函数的时间聚合机制,才能在大数据处理的浪潮中驾驭数据,实现更高效、更精准的数据分析和处理。