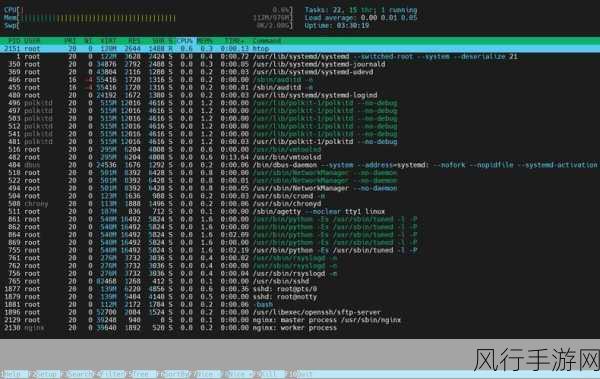
在当今大数据处理领域,Flink 和 Hadoop 都是备受瞩目的技术框架,它们在数据处理和转换方面发挥着重要作用,为企业和开发者提供了强大的工具和解决方案。
Flink 作为一款新兴的流处理框架,以其出色的实时处理能力和高容错性而闻名,Hadoop 则凭借其成熟的生态系统和大规模数据存储能力占据着重要地位。
如何实现 Flink 和 Hadoop 之间的数据转换呢?这是一个值得深入探讨的问题。
我们需要了解 Flink 和 Hadoop 各自的数据存储和处理方式,Hadoop 通常使用 HDFS(Hadoop 分布式文件系统)来存储大规模数据,而 Flink 可以直接从 HDFS 读取数据进行处理,通过 Flink 的 DataSource 接口,我们能够轻松地配置读取 HDFS 中的数据。
对于数据格式的转换,这是一个关键的环节,Hadoop 中常见的数据格式如 Text、Parquet 等,在 Flink 中也有相应的支持,使用 Flink 的 ParquetReader 可以读取 Hadoop 中存储的 Parquet 格式的数据,并进行后续的处理和转换。
在数据转换的过程中,还需要考虑数据的清洗和预处理,Flink 提供了丰富的函数和算子,如 Map、Filter 等,可以对读取的数据进行清洗和筛选,以满足业务需求。
Flink 还支持与 Hadoop 的 YARN 资源管理器进行集成,实现资源的高效分配和管理,这使得在大规模数据处理场景下,能够更好地利用集群资源,提高数据转换的效率和性能。
Flink 和 Hadoop 的结合为大数据处理带来了更多的可能性,通过合理地配置和运用它们的功能,我们能够实现高效、准确的数据转换,为数据分析和业务决策提供有力支持,在实际应用中,根据具体的业务需求和数据特点,选择合适的技术方案和工具,将有助于充分发挥 Flink 和 Hadoop 的优势,创造更大的价值。