Python 的 Scrapy 框架在爬虫开发中备受青睐,而代理的使用在爬虫项目中往往具有重要意义,它不仅能够帮助我们突破访问限制,还能在一定程度上避免被反爬虫机制封禁。
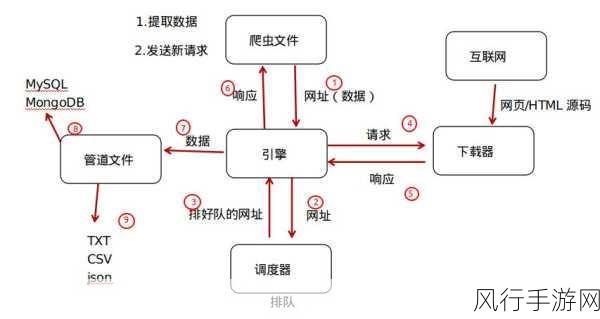
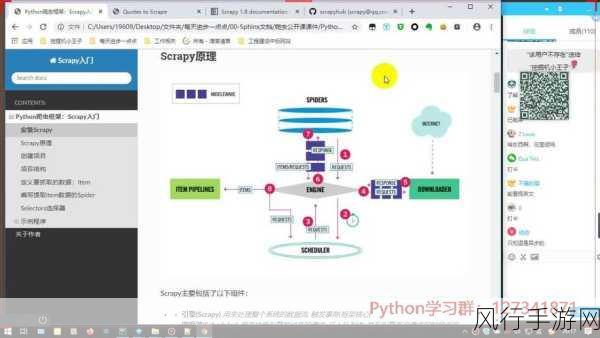
要在 Python Scrapy 爬虫中实现代理使用,需要先明确一些关键概念和准备工作,代理服务器就像是一个中间人,它代替我们去访问目标网站,并将获取到的数据返回给我们,常见的代理类型包括 HTTP 代理和 HTTPS 代理。
我们需要获取有效的代理服务器地址,这可以通过多种途径实现,比如购买专业的代理服务,或者从一些免费的代理网站获取,但需要注意的是,免费代理的稳定性和可用性通常较差,可能会影响爬虫的效率和效果。
在获取到代理服务器地址后,就可以在 Scrapy 项目中进行配置了,在 Scrapy 的设置文件中(通常是 settings.py),需要添加相关的代理设置代码,如果使用 HTTP 代理,可以设置HTTP_PROXY 变量为获取到的代理地址。
配置好代理后,还需要对爬虫进行适当的调整和测试,要确保代理能够正常工作,并且不会影响爬虫的正常逻辑和数据提取。
还需要考虑代理的切换策略,因为单个代理可能会出现故障或者被封禁,所以需要准备多个代理,并实现自动切换的机制,以保证爬虫的持续稳定运行。
Python Scrapy 爬虫中的代理使用是一个需要综合考虑多个因素的过程,只有在充分了解原理和技术细节的基础上,才能有效地运用代理来提升爬虫的性能和稳定性,从而获取到我们所需的数据,但在使用代理进行爬虫开发时,也需要遵守法律法规和网站的使用规则,以确保合法合规地获取数据。