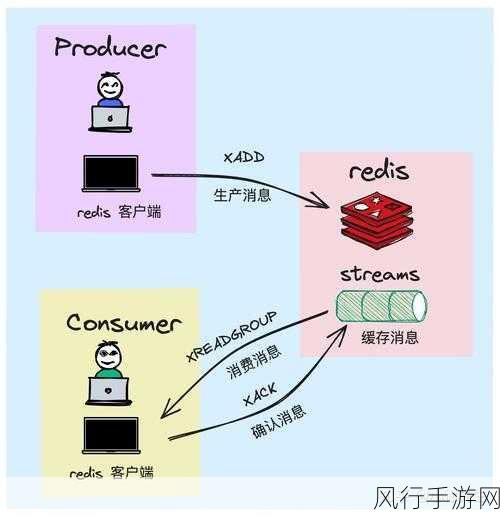
HBase 作为一种分布式的、面向列的数据库,在大数据处理和存储领域有着广泛的应用,而二级索引的使用则能够进一步提升数据查询的效率和灵活性,但在使用过程中也存在一些需要特别注意的地方。
HBase 二级索引并非是一种默认就能够完美适配所有场景的功能,它需要我们在实际应用中进行精心的设计和配置,其实现方式和传统关系型数据库中的二级索引有所不同,在 HBase 中,二级索引通常是通过额外的表或者辅助数据结构来构建的。
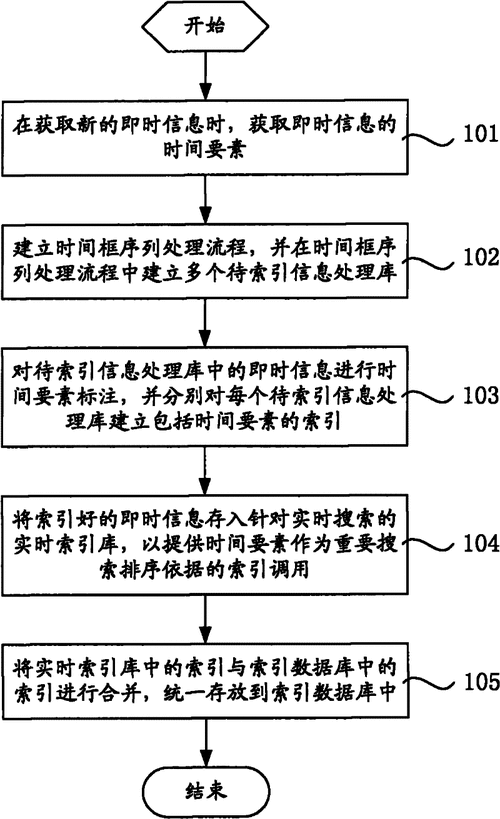
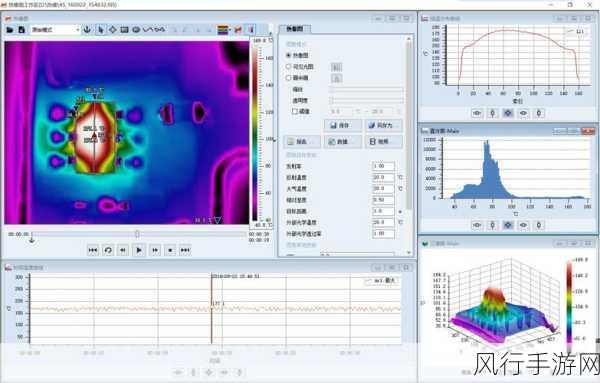
在使用 HBase 二级索引时,要充分考虑数据的分布和存储特点,由于 HBase 是基于分布式架构的,数据在不同的节点上可能会有不同的分布情况,如果二级索引的设计不合理,可能会导致数据的读取和写入出现性能瓶颈,如果索引字段的选择性不高,即该字段的值重复率较高,那么通过这个字段建立的二级索引可能效果就不太理想。
数据一致性也是一个不能忽视的重要问题,当对主表中的数据进行修改、删除或者新增操作时,必须确保二级索引能够同步更新,以保持数据的一致性,否则,可能会出现查询结果不准确或者错误的情况。
二级索引的维护成本也需要纳入考虑范围,构建和更新二级索引会消耗一定的系统资源,如果数据量庞大且更新频繁,那么维护索引的开销可能会相当可观,这就需要在数据的更新频率和查询需求之间找到一个平衡。
还有,索引的选择和创建时机也很关键,不是所有的字段都适合建立二级索引,只有那些经常用于查询条件的字段才有必要建立索引,在数据量较小或者查询需求不复杂的情况下,过早地创建二级索引可能反而会增加系统的负担。
HBase 二级索引虽然能够为数据查询带来便利,但在使用时需要综合考虑多方面的因素,进行合理的设计和优化,才能充分发挥其优势,提升系统的性能和可靠性。