Kafka 作为一种高吞吐量的分布式发布订阅消息系统,在大数据处理和实时数据传输中扮演着至关重要的角色,而 Kafka Coordinator 在其中发挥着关键作用,确保数据能够准确、及时地同步。
要理解 Kafka Coordinator 如何确保数据同步,我们需要先明确一些基本概念,Kafka 中的数据是以分区(Partition)的形式存储和传输的,每个分区都有一个主副本(Leader)和若干个从副本(Follower),数据的写入首先发生在主副本,然后从副本会从主副本同步数据,以保证数据的一致性和可靠性。
Kafka Coordinator 主要通过一系列复杂而精巧的机制来管理和协调这些副本之间的数据同步,其中一个重要的机制是心跳机制,从副本会定期向主副本发送心跳,以表明自己的存活状态和同步进度,主副本则根据这些心跳信息来判断从副本是否正常工作,并决定是否需要进行数据的重新同步或者副本的切换。
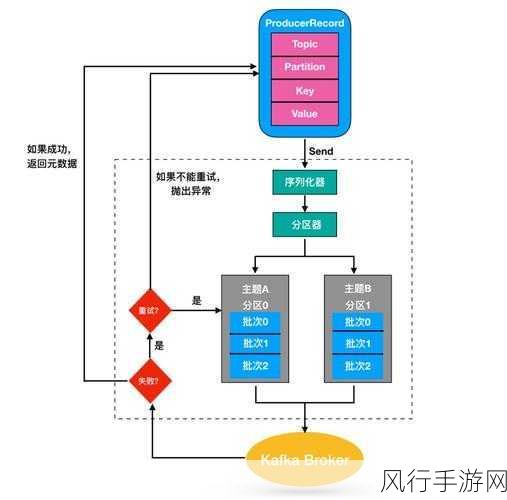
Kafka Coordinator 还会监控副本之间的数据差异,当发现从副本的数据落后于主副本一定程度时,会触发数据的同步操作,这个同步过程是逐步进行的,以避免对系统性能造成过大的冲击,Kafka 采用了一种叫做“偏移量”(Offset)的机制来记录数据的读取和写入位置,通过比较主副本和从副本的偏移量,Kafka Coordinator 能够准确地判断数据的同步状态,并采取相应的措施。
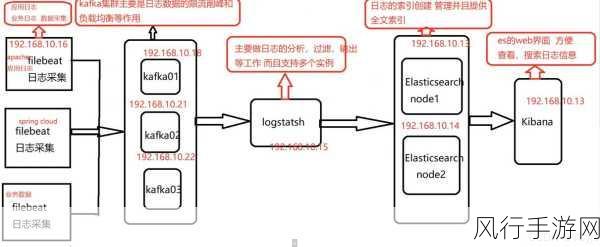
在数据同步过程中,Kafka Coordinator 还需要处理各种异常情况,网络延迟、节点故障等都可能导致数据同步出现问题,针对这些情况,Kafka 具备强大的容错机制,当主副本出现故障时,Kafka Coordinator 会迅速从从副本中选举出新的主副本,以保证数据的持续可用性和同步的进行。
Kafka Coordinator 还会对数据同步的性能进行优化,它会根据系统的负载情况和资源使用情况,动态地调整数据同步的频率和并发度,以在保证数据一致性的前提下,最大限度地提高系统的性能和吞吐量。
Kafka Coordinator 通过心跳机制、数据差异监控、偏移量管理、容错处理以及性能优化等多种手段的协同作用,有效地确保了 Kafka 中数据的同步,这使得 Kafka 能够在复杂的分布式环境中稳定、高效地运行,为各种大数据应用提供了坚实的基础,随着大数据技术的不断发展和应用场景的日益丰富,对 Kafka 数据同步的要求也会越来越高,相信在未来,Kafka Coordinator 还将不断演进和完善,以适应新的挑战和需求。