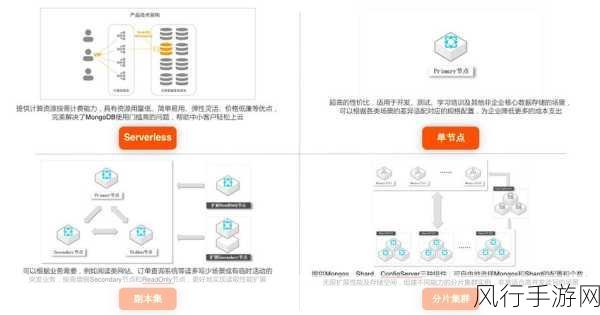
在当今大数据和人工智能蓬勃发展的时代,Spark MLlib 算法作为一款强大的机器学习工具,备受关注,而其中,算法准确率的高低无疑是人们最为关心的问题之一。
Spark MLlib 算法涵盖了众多经典的机器学习算法,如分类、回归、聚类等,其准确率究竟如何呢?要准确评估 Spark MLlib 算法的准确率并非易事,这涉及到多个方面的因素。

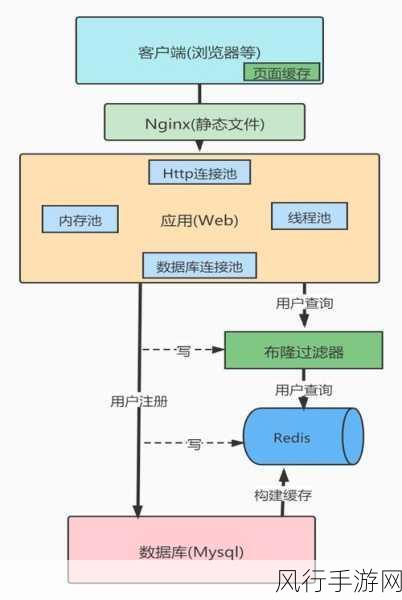
数据的质量和特征工程对准确率有着至关重要的影响,如果输入的数据存在噪声、缺失值或者特征提取不合理,那么即使是再优秀的算法也难以发挥出应有的效果,在处理图像数据时,如果没有进行有效的预处理和特征提取,算法可能会被无关的信息干扰,从而导致准确率下降。
算法的选择和参数调优也直接关系到准确率的高低,不同的问题场景适合不同的算法,例如在处理线性可分的问题时,支持向量机可能表现出色;而对于复杂的非线性问题,神经网络可能更具优势,即使选择了合适的算法,还需要对其参数进行精细的调整,以达到最佳的准确率。
模型的评估指标也会影响对准确率的判断,常见的评估指标有准确率、召回率、F1 值等,在不同的应用场景中,可能需要关注不同的指标来综合评估模型的性能。
在实际应用中,为了提高 Spark MLlib 算法的准确率,我们可以采取一些有效的策略,要对数据进行充分的清洗和预处理,去除噪声和异常值,补充缺失值,并进行合理的特征工程,通过交叉验证等技术进行算法选择和参数调优,结合多种评估指标来全面评估模型的性能,并根据实际需求进行调整和优化。
Spark MLlib 算法本身具有强大的能力,但准确率的高低并非仅仅取决于算法本身,而是受到数据、算法选择、参数调优、评估指标等多方面因素的共同影响,只有在充分理解和掌握这些因素的基础上,我们才能更好地利用 Spark MLlib 算法,获得令人满意的准确率。