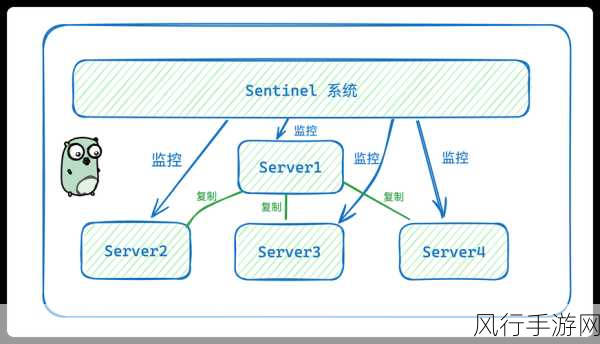
在当今数字化时代,数据处理和分析的需求日益增长,SparkSQL 作为一种强大的工具,在应对海量数据时展现出了卓越的能力,要确保 SparkSQL 在优化过程中的稳定性并非易事。
SparkSQL 的优化是一个复杂且关键的任务,它涉及到多个方面的考量,从数据的存储和读取,到查询计划的生成和执行,每一个环节都可能影响到最终的稳定性。
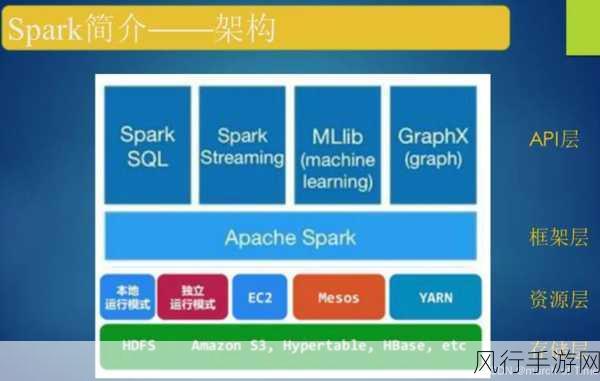
当我们深入研究 SparkSQL 优化以保障稳定性时,必须充分理解其运行机制和底层原理,数据分区策略的选择就至关重要,合理的分区能够减少数据的倾斜,避免某些节点承担过重的负载,从而保障整个系统的平衡运行。
索引的运用也是优化稳定性的重要手段之一,通过创建合适的索引,可以显著提高查询的效率,减少不必要的磁盘 I/O 操作,但需要注意的是,过度创建索引可能会带来维护成本的增加和写入性能的下降,因此需要根据具体的业务场景和数据特点进行权衡。
对于内存的管理也是不容忽视的,SparkSQL 在执行任务时需要消耗大量的内存,如果内存分配不合理,容易导致内存溢出等问题,从而影响系统的稳定性,这就要求我们对任务的内存需求有清晰的认识,并进行合理的配置。
在实际的优化过程中,还需要密切关注资源的使用情况,通过监控 CPU 利用率、内存使用率、网络带宽等指标,及时发现潜在的性能瓶颈,并采取相应的措施进行调整。
对 SparkSQL 的版本升级也可能带来稳定性的提升,新版本往往会修复一些已知的漏洞和性能问题,同时引入新的优化特性,但在升级之前,需要进行充分的测试,以确保新的版本能够与现有系统兼容,并达到预期的优化效果。
保障 SparkSQL 优化的稳定性是一个综合性的任务,需要我们从多个角度进行思考和实践,不断探索和优化,才能让 SparkSQL 在数据处理的舞台上发挥出更加稳定和出色的性能,只有这样,我们才能充分利用 SparkSQL 的强大功能,为企业的数据分析和决策提供坚实的支持。