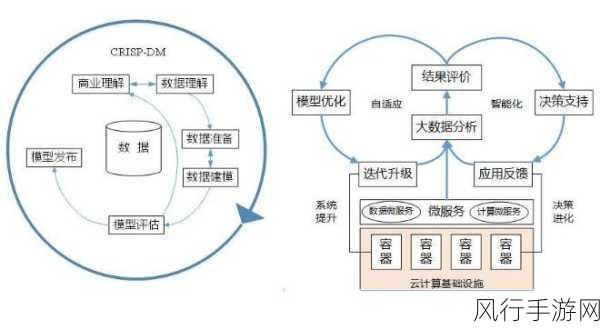
Kafka 作为一款强大的分布式消息队列系统,其分区配置是实现高效数据处理和存储的关键环节,在实际应用中,正确合理地配置分区对于系统的性能和可靠性有着至关重要的影响。
要理解 Kafka 分区配置,我们需要先明晰分区的基本概念,分区本质上是将主题的数据分割成多个逻辑上独立的部分,从而实现数据的并行处理和存储,每个分区都可以在不同的 Broker 上存储和处理,这为系统提供了出色的可扩展性和容错性。
如何进行有效的分区配置呢?这需要综合考虑多个因素,首先是数据量和吞吐量,如果预计数据量较大且处理速度要求高,那么就需要创建更多的分区来分散数据处理压力,其次是消费者的数量和处理能力,如果有多个消费者同时处理数据,且每个消费者的处理能力有限,那么适当增加分区数量可以使每个消费者都能更高效地获取数据进行处理。
还需要考虑数据的分布特性,如果数据具有明显的分布规律,比如按照时间或者地域分布,那么可以根据这些规律来进行分区配置,以提高数据处理的效率和查询性能。
在实际配置分区时,我们可以通过 Kafka 的配置文件或者相关的管理工具来进行操作,修改 broker 的配置文件中的 num.partitions 参数来指定主题的初始分区数量。
要注意分区数量也不是越多越好,过多的分区可能会导致管理成本增加、资源消耗过大以及数据一致性等问题,在进行分区配置时,需要进行充分的测试和评估,根据实际的业务需求和性能指标来找到一个最佳的平衡点。
消息队列 Kafka 的分区配置是一项复杂但又至关重要的任务,只有深入理解业务需求和 Kafka 的工作原理,结合实际的测试和优化,才能实现高效、可靠的分区配置,为系统的稳定运行和业务的发展提供有力支持。