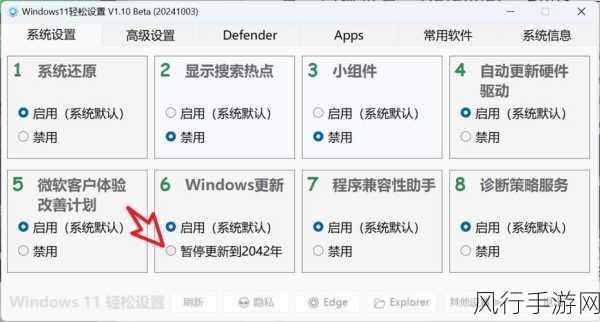
在当今大数据处理领域,Spark 和 Hive 都是备受关注的工具,但究竟哪一个在性能方面更具优势呢?这是许多数据工程师和分析师常常思考的问题。
要比较 Spark 和 Hive 的性能,我们需要先了解它们的工作原理和特点,Hive 最初是基于 MapReduce 框架构建的,它将类 SQL 的查询语句转换为一系列的 MapReduce 任务来执行,这种方式在处理大规模数据时具有一定的稳定性,但由于 MapReduce 本身的局限性,其性能在某些情况下可能不尽如人意。
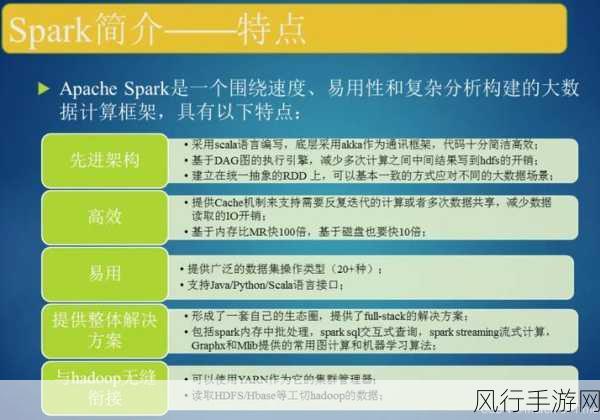
Spark 则是一种基于内存计算的大数据处理框架,它具有更高的并行处理能力和更快的执行速度,Spark 能够将数据缓存在内存中,从而减少了磁盘 I/O 操作,大幅提高了数据处理的效率。
从数据处理的速度来看,Spark 在大多数情况下表现得更为出色,特别是对于需要多次迭代计算的任务,Spark 凭借其内存计算的优势,可以迅速完成计算,而 Hive 可能需要较长的时间。
性能的优劣并不仅仅取决于处理速度,在数据量较小或者对数据准确性要求极高的场景中,Hive 的稳定性和可靠性可能会更受青睐。
资源的利用效率也是评估性能的重要因素之一,Spark 在资源分配和管理方面更加灵活,可以根据任务的需求动态调整资源的使用,而 Hive 在这方面相对较为固定,可能会导致资源的浪费或者不足。
在实际应用中,选择 Spark 还是 Hive 往往取决于具体的业务需求和数据特点,如果是需要快速处理大规模数据、进行实时分析或者复杂的机器学习任务,Spark 可能是更好的选择,但如果数据量不大、对数据的准确性和稳定性要求较高,并且处理逻辑相对简单,Hive 则可能更适合。
Spark 和 Hive 都有各自的优势和适用场景,不能简单地一概而论哪一个性能更好,在实际的数据处理工作中,需要根据具体情况进行综合评估和选择,以达到最佳的性能和效果。