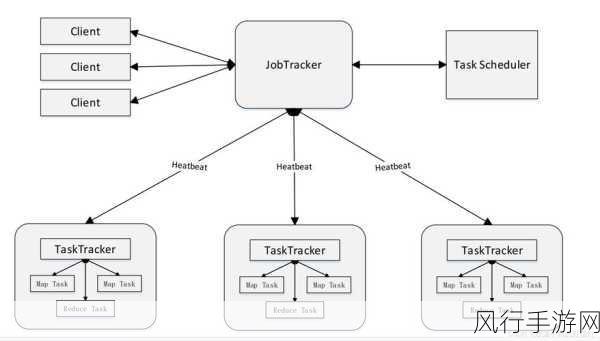
在当今数字化时代,数据的产生和处理规模呈爆炸式增长,大数据处理技术成为了企业和组织获取有价值信息的重要手段,而 Kafka 作为一种高性能的分布式消息队列系统,其序列化和反序列化功能在大数据处理中发挥着至关重要的作用。
Kafka 中的序列化是将数据结构或对象转换为适合在网络中传输或存储的二进制格式的过程,反序列化则是将二进制数据转换回原始的数据结构或对象,这两个过程就像是数据在 Kafka 世界中的“变形术”,使得数据能够高效、准确地在系统中流动。
在大数据处理场景中,数据来源多种多样,格式千差万别,Kafka 的序列化和反序列化功能能够有效地将这些不同格式的数据进行统一处理,确保数据的一致性和可读性,来自传感器的实时数据、用户的行为数据以及系统日志等,都可以通过序列化转换为统一的格式,方便后续的存储和处理。
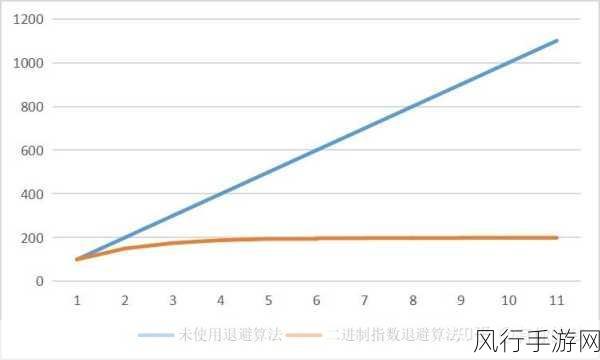
序列化和反序列化还能够优化数据的存储和传输效率,通过压缩和编码数据,可以大大减少数据的存储空间和网络传输带宽的消耗,这对于处理海量数据的大数据系统来说,是至关重要的性能优化手段。
Kafka 的序列化和反序列化机制还提供了良好的扩展性和兼容性,随着业务需求的变化和新的数据格式的出现,可以方便地添加新的序列化和反序列化器,以适应不断变化的业务场景。
在数据安全方面,序列化和反序列化过程可以对数据进行加密和解密操作,保障数据在传输和存储过程中的安全性和隐私性。
Kafka 序列化和反序列化在大数据处理中扮演着不可或缺的角色,它们不仅实现了数据的高效传输和存储,还为大数据处理系统的灵活性、扩展性和安全性提供了有力的支持,在未来,随着大数据技术的不断发展和创新,Kafka 的序列化和反序列化功能也将不断完善和优化,为大数据处理带来更多的可能性和价值。