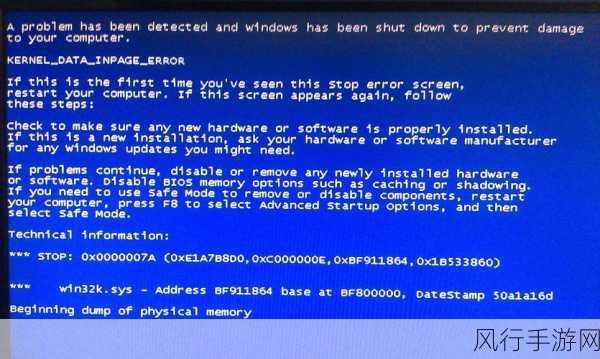
Redis 作为一种高性能的键值对存储数据库,其数据结构的多样性和灵活性是其强大功能的重要支撑,Redis 中的数据结构并非一成不变,它们在不同的应用场景和需求下会发生相应的变化。
Redis 提供了多种数据结构,如字符串(String)、哈希(Hash)、列表(List)、集合(Set)和有序集合(Sorted Set)等,这些数据结构各自有着独特的特点和适用场景。
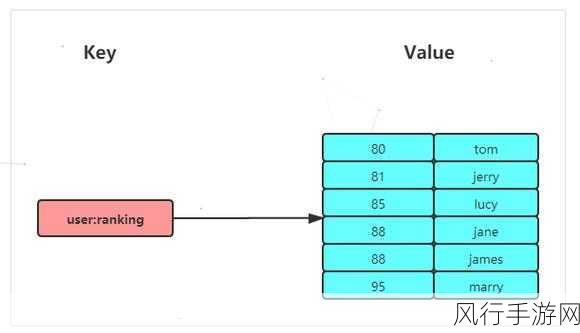
以字符串为例,它可以用于存储简单的键值对数据,如用户的登录状态信息、配置参数等,但当需要存储更复杂的结构化数据时,哈希结构就派上了用场,哈希能够将一组相关的键值对存储在一个字段中,方便对数据进行分组和管理。
列表结构适合实现队列、栈等数据结构,比如消息队列的实现就可以借助列表,集合则用于存储不重复的元素,常用于去重操作,有序集合在集合的基础上增加了元素的排序功能,适用于排行榜等场景。
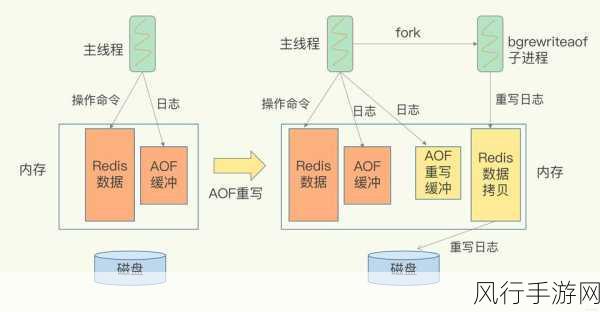
在实际应用中,Redis 数据结构的变化并非仅仅取决于数据的类型和规模,还受到性能需求、数据访问模式等多种因素的影响。
当数据量不断增长,原本使用的某种数据结构可能会出现性能瓶颈,就需要考虑对数据结构进行调整或转换,将大量的小哈希合并为一个大哈希,以减少内存开销和提高查询效率。
数据的访问模式也会影响数据结构的选择和变化,如果经常需要对数据进行范围查询,那么有序集合可能是更好的选择;如果需要快速的随机访问,字符串可能更合适。
理解和掌握 Redis 数据结构的变化规律,需要深入了解其各种数据结构的特点和适用场景,并结合实际的业务需求和性能要求进行灵活运用和优化,只有这样,才能充分发挥 Redis 的优势,为应用提供高效、可靠的数据存储和处理服务。