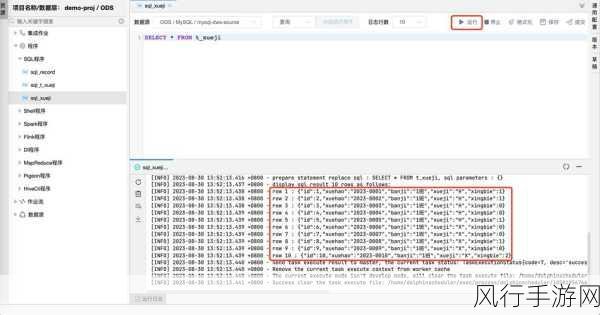
Kafka 作为一种强大的分布式消息队列系统,在现代的大数据处理和分布式应用中扮演着至关重要的角色,而其中的 GroupID 更是一个关键的概念,它决定了消费者组的行为和消息的分配方式。
Kafka 的 GroupID 到底有没有默认值呢?答案是有的,默认情况下,如果在创建消费者时没有明确指定 GroupID,Kafka 会为其生成一个随机的 GroupID。
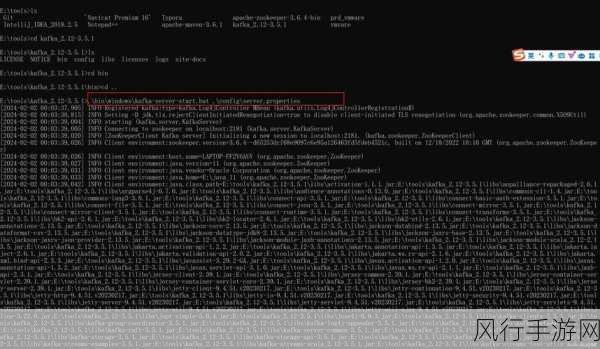
这种随机生成的默认 GroupID 具有一定的优势,它可以避免在某些情况下,由于开发者的疏忽或者未充分考虑而导致的 GroupID 冲突问题,当多个消费者实例在不同的应用或者进程中运行时,如果都没有指定 GroupID,随机生成能够确保它们不会意外地属于同一个消费者组,从而避免了消息分配和处理的混乱。
随机默认 GroupID 也可能带来一些挑战,对于需要对消费者组进行明确管理和监控的场景,随机生成的 GroupID 使得追踪和识别特定的消费者组变得困难,因为每次创建新的消费者时,生成的 GroupID 都是不可预测的。
如果应用程序的逻辑依赖于特定的消费者组行为,而使用了随机的默认 GroupID,可能会导致意外的结果,可能期望多个消费者协同工作来处理消息,但由于随机的 GroupID 导致它们被分配到了不同的消费者组,从而无法实现预期的协同效果。
为了更好地控制和管理 Kafka 中的消费者组,建议在实际应用中总是显式地指定 GroupID,这样可以提高系统的可预测性和可管理性,也便于在出现问题时进行故障排查和性能优化。
指定明确的 GroupID 还能够与其他的系统组件或监控工具更好地集成,一些监控系统可能需要根据已知的 GroupID 来收集和分析消费者组的性能指标和行为数据。
虽然 Kafka 为 GroupID 提供了随机生成的默认值,但在大多数实际应用场景中,为了实现更精确的控制和管理,开发者应该根据具体的业务需求和系统架构,谨慎地选择并指定合适的 GroupID,只有这样,才能充分发挥 Kafka 强大的消息处理能力,构建出高效、可靠的分布式应用系统。