在当今数字化的时代,数据的价值日益凸显,而 Python 爬虫作为一种获取数据的有效手段,其能否实现自动化成为了许多人关注的焦点。
Python 爬虫具有强大的功能和灵活性,这使得它在实现自动化方面具备了一定的优势,它可以模拟人类在网页上的操作,自动访问网页、提取所需的数据,并按照预设的规则进行处理和存储。

要理解 Python 爬虫能否实现自动化,我们需要先明确什么是自动化,自动化意味着在无需人工持续干预的情况下,系统能够按照预定的流程和规则完成一系列任务,对于 Python 这意味着它能够自动识别目标网页的结构,定位所需数据的位置,并准确地抓取和处理这些数据。
Python 爬虫实现自动化的关键在于编写高效、准确的代码,开发者需要熟练掌握 Python 的相关库和技术,如 requests 库用于发送 HTTP 请求,BeautifulSoup 或 lxml 库用于解析网页内容等,通过合理运用这些工具,开发者能够构建出功能强大的爬虫程序,实现自动化的数据抓取。
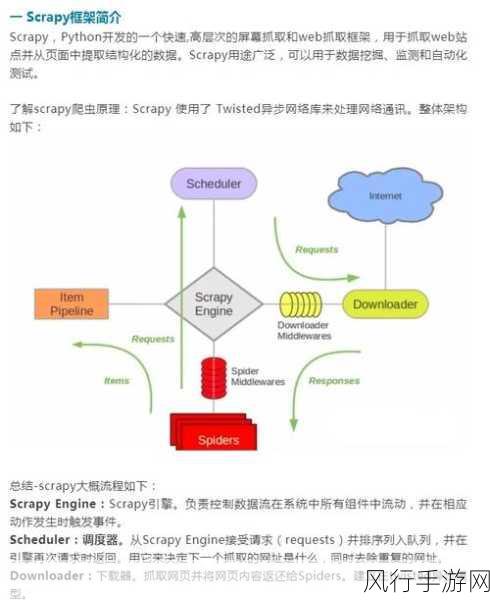
自动化的 Python 爬虫还需要考虑到反爬虫机制,许多网站为了保护自身的数据和服务,会采取各种反爬虫措施,如限制访问频率、验证码验证等,为了确保爬虫的顺利运行,开发者需要研究和应对这些反爬虫机制,采用合适的策略,如设置合理的请求间隔、使用代理 IP 等。
数据的合法性和道德性也是在实现 Python 爬虫自动化时必须要重视的问题,在抓取数据时,必须遵守法律法规和网站的使用规则,不得侵犯他人的权益和隐私。
Python 爬虫在正确的技术和策略支持下,是能够实现自动化的,它为我们获取和处理大量数据提供了便捷的途径,但同时也需要我们谨慎使用,确保合法合规、道德合理,随着技术的不断发展和完善,相信 Python 爬虫的自动化应用将会在更多领域发挥重要作用,为我们的生活和工作带来更多的便利和创新。