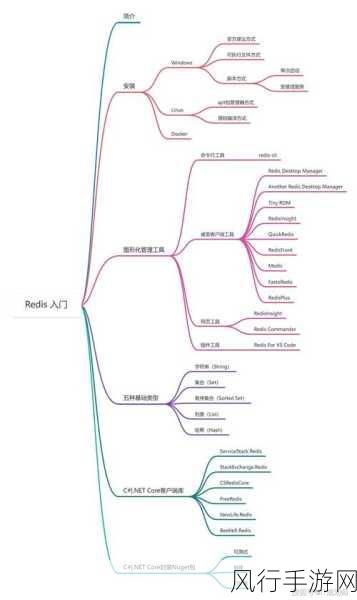
Hive 数据库作为大数据处理领域的重要工具,其在数据挖掘方面具有强大的能力和广泛的应用,数据挖掘旨在从海量的数据中发现有价值的信息和模式,而 Hive 数据库为实现这一目标提供了有力的支持。
Hive 数据库基于 Hadoop 生态系统,能够处理大规模的数据,它使用类似于 SQL 的查询语言,使得熟悉传统数据库操作的用户能够较为轻松地进行数据处理和分析,在数据挖掘过程中,数据的预处理是至关重要的一步,通过 Hive 数据库,可以对原始数据进行清洗、转换和集成,去除噪声和重复数据,将数据整理成适合挖掘的格式。
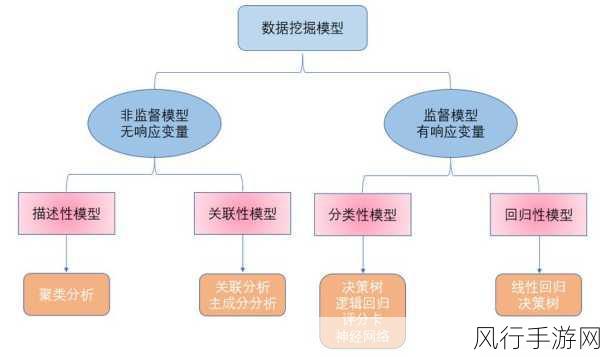
在特征工程方面,Hive 数据库能够帮助提取和构建有意义的特征,通过聚合、计算衍生指标等操作,将复杂的数据转化为更具代表性的特征,为后续的挖掘算法提供更好的输入。
分类和预测是数据挖掘中的常见任务,利用 Hive 数据库,可以基于历史数据构建分类模型,预测未来的趋势或结果,常见的算法如决策树、朴素贝叶斯等,可以在 Hive 中通过编写相应的查询语句来实现。
关联规则挖掘也是 Hive 数据库的一个重要应用场景,通过分析数据中不同项之间的关联关系,可以发现隐藏在数据中的有趣模式,在电商领域,可以找出经常一起购买的商品组合,为推荐系统提供依据。
聚类分析同样能够在 Hive 数据库中得以实现,将相似的数据点聚集到不同的簇中,有助于发现数据中的自然分组和结构。
在实际应用中,为了提高数据挖掘的效率和效果,还需要结合其他技术和工具,使用数据可视化工具来直观地展示挖掘结果,便于理解和分析;或者利用机器学习框架与 Hive 数据库进行集成,充分发挥各自的优势。
Hive 数据库为数据挖掘提供了强大的平台和工具,通过合理运用其功能和技术,能够深入挖掘数据中的价值,为企业决策、业务优化等提供有力的支持,但同时,也需要不断学习和探索,以适应不断变化的数据挖掘需求和技术发展趋势。